


Hey Adopter,
I keep running into the same problem when I advise businesses on AI. The AI isn’t the bottleneck. The data is.
Most companies I work with have their information scattered across 10 to 20 different tools. Salesforce has the customer data. QuickBooks has the financials. HubSpot has marketing. Slack has conversations. None of them talk to each other. When someone asks “what did we spend on customer acquisition last quarter?”, three people pull three different numbers from three different systems. That’s the real reason AI projects stall. You can’t build anything intelligent on top of data that’s fragmented, duplicated, and inconsistent.
So I went and investigated what it actually costs to fix this. Not the vendor pitch version. The real version, with verified numbers, public filings, and the pricing pages they hope you never read. What I found was worse than I expected.
This article breaks down the true cost of a “proper” data infrastructure for a mid-size company, why you keep getting sold tools you don’t need, what you actually need instead (it fits on a napkin), and where the market is heading. It’s a long one. Worth it.
Let’s start with a number that should scare you.
If this hits close to home, forward it to whoever owns the data conversation at your company. And if you want to talk through your situation, reply to this email. I advise businesses on this and I’m happy to get on a call.
Someone forgot to check the meter
A 200-person company got a $60,000 monthly Snowflake bill. Not because they were doing anything ambitious. Queries nobody knew were running had been racking up compute for weeks. No alerts. No guardrails. No one watching.
That’s $720,000 a year. On accident.
You’d think this was a freak event. It’s not. It’s consumption-based pricing doing what consumption-based pricing does. The meter runs whether you’re looking or not. And Snowflake’s billing minimum charges you for 60 seconds of compute even when your query takes three. Run ten dashboard refreshes at three seconds each, you pay for ten full minutes. For BI-heavy workloads, that means paying up to 20x the compute you use.
This isn’t a bug. It’s the business model. And it’s working perfectly, for them.
The real math nobody puts on the first slide
Your CTO says you need a “proper data stack.” Your board agrees. A consultant nods along. A vendor shows up with a deck full of logos and a quote that looks reasonable. Here’s what reasonable turns into for a 200-person company once you follow the money all the way to the end.
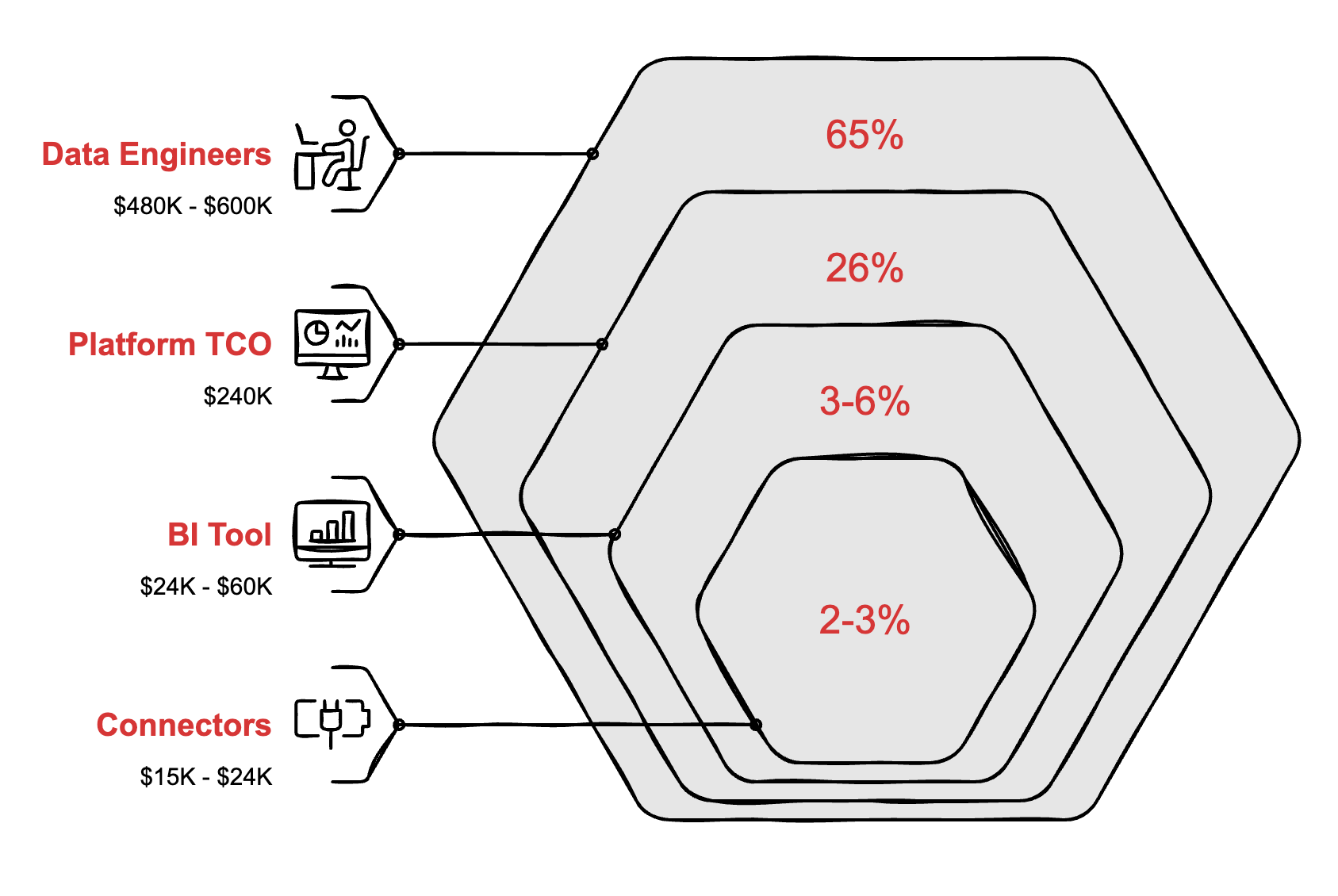
The platform. Snowflake’s median annual contract is $100,000, based on 633 real purchases tracked by Vendr. But the sticker price is a fraction of the real cost. A MotherDuck analysis found the true total cost of ownership runs 2.4x higher once you account for compute overhead, the 60-second billing minimum, and egress fees. Your $100K platform is closer to $240K.
The connectors. Your data lives in Salesforce, HubSpot, QuickBooks, Slack, and a dozen other tools. You need something to pull it all together. Fivetran will do it for $15,000 to $24,000 a year. Unless you need more than a few connectors, in which case their March 2025 pricing restructure hit multi-source setups with 40-70% cost increases. 35% of G2 reviewers now cite cost as their top complaint.
The dashboards. Looker or Tableau with enough seats to be useful: $24,000 to $60,000 a year. Less than that and you’ve built an expensive system only three people can access.
The people. This is where it gets ugly. You need a minimum of three data engineers to keep the lights on. At $125,000 to $136,000 base salary, fully loaded with benefits and overhead, that’s $160,000 to $200,000 per head. Three of them: $480,000 to $600,000 a year.
Add it up.
Component Annual cost Snowflake (true TCO) $240,000 Fivetran connectors $15,000 - $24,000 BI tool $24,000 - $60,000 3 data engineers (fully loaded) $480,000 - $600,000 Total $760,000 - $924,000
For a 200-person company. Before you’ve produced a single report anyone trusts.
And here’s the part that should make you angry: at one company, 3 of 8 data engineers spent 80% of their time keeping the stack running. Not building anything. Not analysing anything. Maintenance. That’s IT support with a fancier job title and a $180K salary.
Why you keep buying it anyway
Three forces keep this cycle spinning.
The vendor’s incentives point away from yours. Snowflake’s revenue grows when your queries are inefficient. That’s not a conspiracy theory. It’s their business model, filed with the SEC. Instacart’s Snowflake bill went from $13 million to $51 million in two years before they brought in a dedicated team to claw it back through optimisation. They got it down to a projected $15 million, which means roughly $36 million of that spend was waste. Instacart has hundreds of engineers. You have maybe two. The vendor has no reason to tell you you’re overspending. You are the margin.

Fear of being wrong. “Nobody got fired for buying Snowflake” is the 2026 version of “nobody got fired for buying IBM.” Your CTO recommends it because it’s the safe choice, not the right one. The name carries the meeting. The invoice carries the budget. And when the board asks “are we doing data right?”, pointing at a Snowflake logo feels safer than explaining why you chose something they’ve never heard of.
The buzzword tax. “AI-ready data” is the phrase doing the most damage right now. Every vendor pitch in 2026 includes it. Only 6% of enterprise AI managers say their data infrastructure is actually ready for AI. Six percent. Because “AI-ready” means clean, unified, queryable data. That’s it. Every warehouse does that. The label is marketing, not a capability. You’re paying a premium for a sticker on the same box.
What you need fits on a napkin
Strip the jargon and a 200-person company needs four things.
Your SaaS tools connected to one place. Salesforce, HubSpot, QuickBooks, your HRIS, all feeding into a single source. That’s integration.
Duplicates resolved, names consistent. “John Smith” in Salesforce and “J. Smith” in QuickBooks are the same person. Your system should know that. That’s entity resolution and cleaning.
Someone can ask questions without writing SQL. Whether that’s a BI dashboard or an AI chat interface, the point is the same. A non-technical person asks a question, gets a trustworthy answer. Not “let me file a ticket with the data team and wait three days.”
Someone knows what data exists and who can see it. Governance. Not glamorous. Absolutely necessary. When your sales VP can see payroll data because nobody set permissions, that’s not a feature.
That’s the list. Four items. Yes, somewhere under the hood there’s a data lake or a warehouse. You don’t need to know which one, how it works, or what Apache Iceberg is. You have gigabytes of data, maybe low terabytes. The industry is selling you a fire truck when you need a garden hose.
And yet 67% of organisations don’t trust their own data enough to make decisions with it. They spent the money. Built the stack. Hired the engineers. Still can’t get a straight answer about last quarter’s revenue without three people arguing over spreadsheets. The problem was never the size of the platform. It was whether anyone could use it.
The cracks are showing
The big vendors won’t frame it this way, but the numbers tell the story.
Snowflake’s net revenue retention dropped from 131% to 126% in 12 months. Existing customers are spending less. They added 1,735 new customers in FY2025, but those customers are smaller. The growth engine is sputtering where it used to roar.
Fivetran’s pricing overhaul drove engineers to Reddit looking for alternatives. “Fivetran has a reputation for being eye-wateringly expensive” is a direct quote from r/dataengineering, and it’s one of the polite ones.
Only 23% of data projects finish on time and on budget. The rest blow past deadlines, burn through cash, or get quietly abandoned. And 21% of companies replaced their data platform entirely in 2024. One in five. That’s not normal churn. That’s buyer’s remorse at scale.
Meanwhile, the ground is shifting underneath. DuckDB grew 136% year-over-year in the Stack Overflow developer survey, hitting 25 million monthly PyPI downloads. It’s open-source, runs on a laptop, and handles the analytical workloads that 90% of mid-market companies will ever throw at it. MotherDuck, the cloud version, raised $133 million in total funding. A company called Definite offers a complete data stack for $250 a month.
The market is voting with its wallet. And it’s voting against complexity.
Startups are spending $100,000 a year on modern data stacks before generating a single meaningful business result. That number used to be the cost of doing business. Now it’s the cost of doing it wrong.
A new category is emerging. One vendor, one contract. Connectors, cleaning, modelling, dashboards. No engineers required. This category barely existed two years ago. It’s real now.
The gap nobody’s filled yet
Here’s where you sit today.
The enterprise stack costs $760,000 to $924,000 a year and requires a team to operate. You know this because you’re either paying it or you’ve been quoted something close.
The lean DIY approach, DuckDB plus Airbyte plus a BI tool plus duct tape, costs $80,000 to $140,000 a year. But it requires someone technical to stitch together four or five tools and keep them running. When a connector breaks at 2am, that’s your problem. When Fivetran changes its pricing, that’s your problem. When two tools update their APIs on the same week and nothing syncs, that’s a Tuesday. Reddit’s honest assessment of enterprise data tools for mid-market companies: “overkill unless you have 50 people in your data team.”
There should be something in the middle. Not a stack you assemble from parts. An end-to-end data platform, one vendor that handles everything. You pay more than DIY because you’re paying for “I never think about data infrastructure again.” You pay dramatically less than enterprise because you’re not funding three engineers and a Snowflake habit. You get clean, unified data without learning what a DAG is.
That option barely existed two years ago. It’s emerging now. The companies that find it first will spend a fraction of what the enterprise stack costs, ship faster, and never post a job listing for a data engineer.
The question for 2026 isn’t which data stack to build. It’s whether you need to build one at all.
Adapt & Create,
Kamil





