

Hey Adopter,
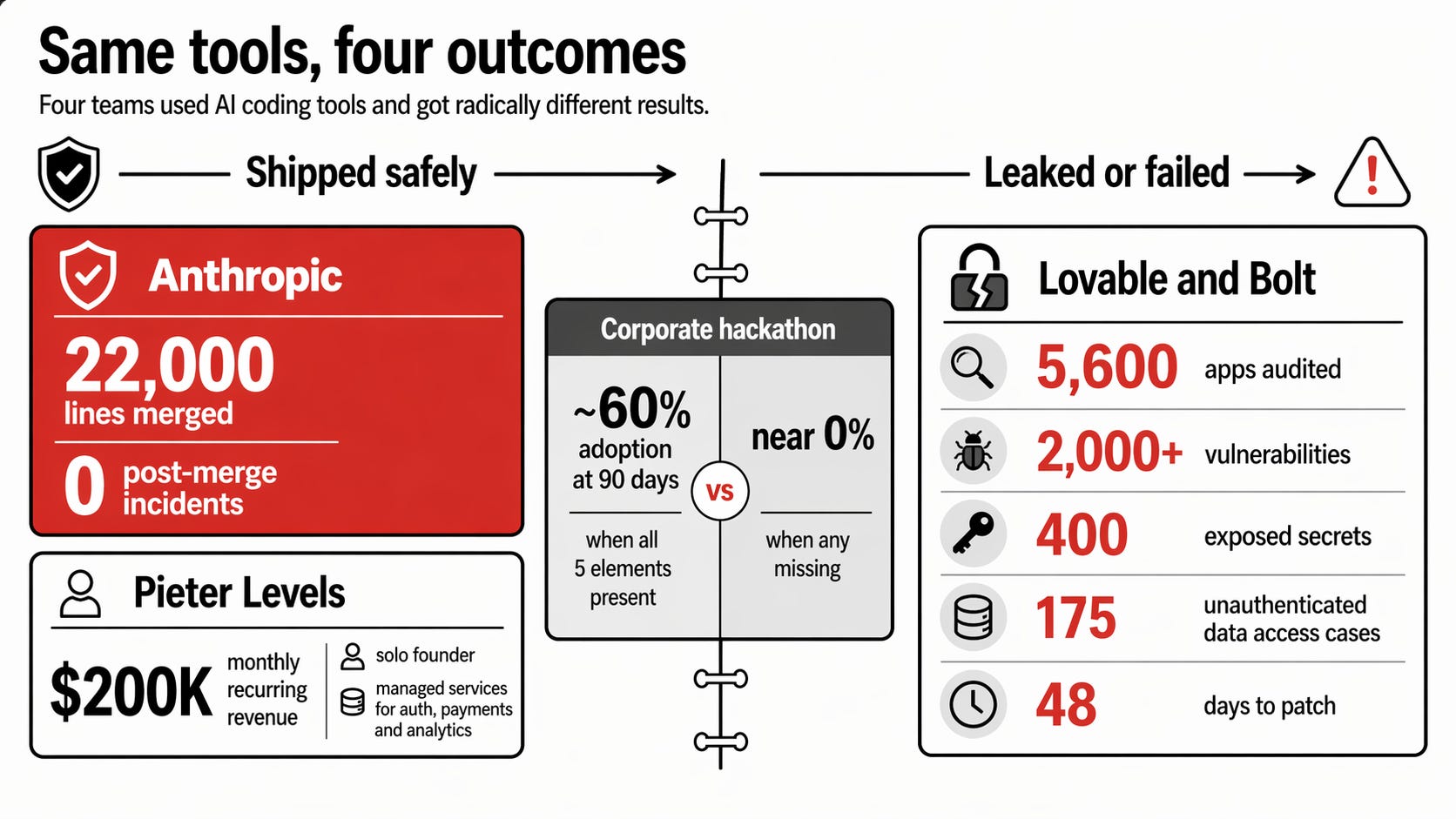
Two numbers landed on my desk this month and sat next to each other like an indictment. Anthropic merged a 22,000-line pull request, written mostly by Claude, into their offline reinforcement-learning codebase. Shipped clean. Zero post-merge incidents.
The same month, Escape Analysis published their audit of 5,600 vibe-coded applications and found 2,000 vulnerabilities, 400 exposed secrets, and 175 production apps serving unauthenticated data to anyone who asked.
Lovable left a user data leak open for 48 days before patching it. Bolt was not far behind. Same models. Same tools. The gap between those two outcomes is the whole subject of this edition.
The say-do gap
The headline numbers from Veracode’s 2025 GenAI Code Security Report are ugly. Forty-five percent of AI-generated code contains detectable vulnerabilities at the moment of generation.
The Cloud Security Alliance puts the figure higher at 62 percent. Georgia Tech’s CVE (Common Vulnerabilities and Exposures) tracker logged 35 new CVEs in March 2026 traced directly to AI-generated code. More than double February’s count. Six times January’s. The trend line is not flattening.
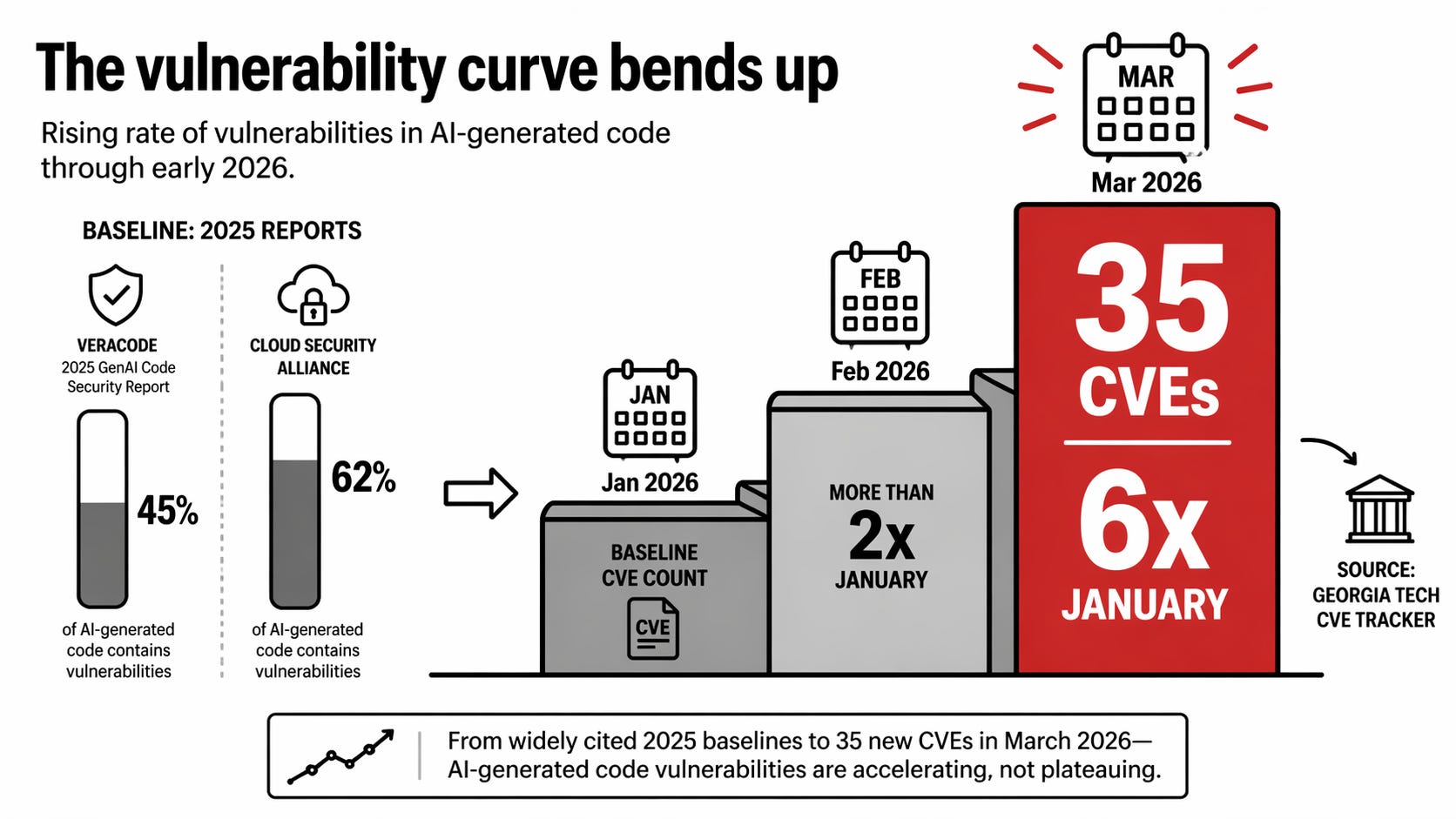
Meanwhile the other side of the ledger keeps ticking up. Claude Opus 4.7 hit 87.6 percent on SWE-bench Verified on 16 April. Cursor 3 shipped on 2 April with agent workflows that keep a whole codebase loaded at once. GPT-5.5 landed on 23 April. The models are pulling away from the median human developer on contained tasks. They are also generating more broken code at scale than any team of humans ever has.
Both things are true at once, which is why executives are confused and security teams are furious. The chief information security officer sees 62 percent of output needing a scrub. The head of engineering sees a 10x productivity bump on greenfield features. Both are looking at the same model. They are measuring different slices of the same output.
What separates the companies shipping cleanly from the companies writing incident reports is not the model. It is everything around the model. Permission. Scope. A spotter. Maintenance ownership. The discipline to treat a language model as a fast junior with zero taste rather than a senior engineer with a keyboard. This edition is about that gap.
Schluntz called this in May 2025
Erik Schluntz gave a talk at Code with Claude eleven months ago titled “Vibe Coding in Prod (Responsibly).” Four principles. No jargon. I have watched it three times this year, and every time someone in the audience of a client workshop asks me what the right way to think about this actually is, I send them that link.
Principle one. Be Claude’s PM. Do not type the code. Plan the work, decompose the task, write the ticket you would hand to a junior. Schluntz argued that humans spend ninety percent of their time typing and ten percent planning. Vibe coding inverts that ratio. The typing is cheap now. The planning is where the value moves.
Principle two. Target leaf nodes. Pick parts of the codebase that nothing else depends on. Utilities. Scripts. Isolated services. When Claude breaks a leaf node, the blast radius is contained. When Claude changes a core abstraction, the blast radius is everything.
Principle three. Verify behaviour, not implementation. Do not read every line of generated code hunting for bugs. Write tests and harnesses that stress the output. Run the thing. Check the outputs. Trust the behaviour envelope, not your ability to spot subtle flaws in code you did not write.
Principle four. Embrace exponentials. The models are getting better fast. Build habits that scale with the tooling. Do not optimise your process around a six-month-old model capability.
That talk is the intellectual spine of every case below. Schluntz was right eleven months early. The community caught up this spring because the model numbers finally justified his confidence. Opus 4.7 at 87.6 percent on SWE-bench Verified is the benchmark Schluntz was writing toward. His four principles aged well because they were never about the model. They were about the human workflow around the model.
Four cases, one pattern
Anthropic’s 22,000-line merge. Offline reinforcement-learning codebase. The team spent days planning before Claude wrote a line. Decomposed into leaf nodes. Human review concentrated on the core architecture. Stress tests verified behaviour across everything else. The result was a merge that would have taken weeks by hand, shipped in days, zero post-merge incidents. The Claude team is the one company whose workflow is worth copying on this, because they built the thing and live with the consequences.
Pieter Levels at $200K monthly recurring. Solo founder, no employees, ships consistently. What he does not vibe code matters as much as what he does. Auth sits on Clerk. Payments sit on Stripe. Analytics sits on Plausible. He vibe codes the product surface on top of managed services that handle the dangerous parts. Bounded scope, small products, ruthless about what stays in. That is not laziness. That is discipline that looks like laziness. His public record is at levels.io.
The corporate hackathon that sticks. I have run a few and watched more. The ones where teams are still using the tools 90 days later share five things. Three to four non-technical builders per team. One technical spotter who reviews before deployment. Explicit executive permission at the start, said out loud. Real problems from the builder’s own department, not invented exercises. A 30-day deployment phase that nobody skips. Hit all five and adoption runs around 60 percent. Miss any single one and it collapses to near zero.
Lovable and Bolt leaked for 48 days. Escape Analysis audited 5,600 vibe-coded apps. The pattern was consistent. No spotter. No security review step. Non-technical builders optimising for “does it work when I use it” and shipping to production with their thumbs up. The 48-day window is not a story about bad models. It is a story about missing permission structure, no defined owner, and no review layer between prompt and deploy. The models did what they were asked. Nobody asked the right questions.
The tools are the same across all four cases. What changed is everything around the tools.
Five patterns that decide which side you end up on
Pattern one. A spotter is non-negotiable for anyone non-technical. Half an hour of developer time across a whole project. One review pass before deployment. That single step catches the Veracode 45 percent almost in full. Skip it and the 48-day window becomes your most likely outcome.
Pattern two. Scope selection is the skill, not prompting. Every case that shipped safely started with a narrow problem where the worst-case failure was a wasted afternoon. The teams that collapsed were building user-facing production apps on day one. Pick small. Stay small. Graduate slowly.
Pattern three. Verifiability beats review. Reading generated code line by line is how engineers who grew up writing code themselves try to adapt. It does not scale and it misses things. Tests, observable inputs and outputs, stress harnesses. Check the behaviour envelope. Schluntz was right in May 2025 and he is still right.
Pattern four. Maintenance ownership is assigned before the first line is written. Day 90 is where the silent failures live. Someone leaves. The tool breaks. Nobody remembers who built it or how. Assign the owner on day zero, or you are building something that will fail silently later while everyone celebrates the initial win.
Pattern five. The licence-to-habit bridge requires explicit permission. Companies buy Cursor seats. Seats sit unused. The missing ingredient is not training. It is a named executive saying out loud “you are allowed to use this on real work.” Everything downstream, adoption, confidence, velocity, depends on that sentence being spoken.
The full case study
Everything above is distilled from a 16-page case study report I put together this week. Full cases, the tool picture as of April 2026, the benchmark numbers with sources, and the uncomfortable truths vendor content skips. Attached to this post as a PDF. Grab it.
The kit for paid subscribers
The PDF is the analysis. The kit is the tools you use on Monday.
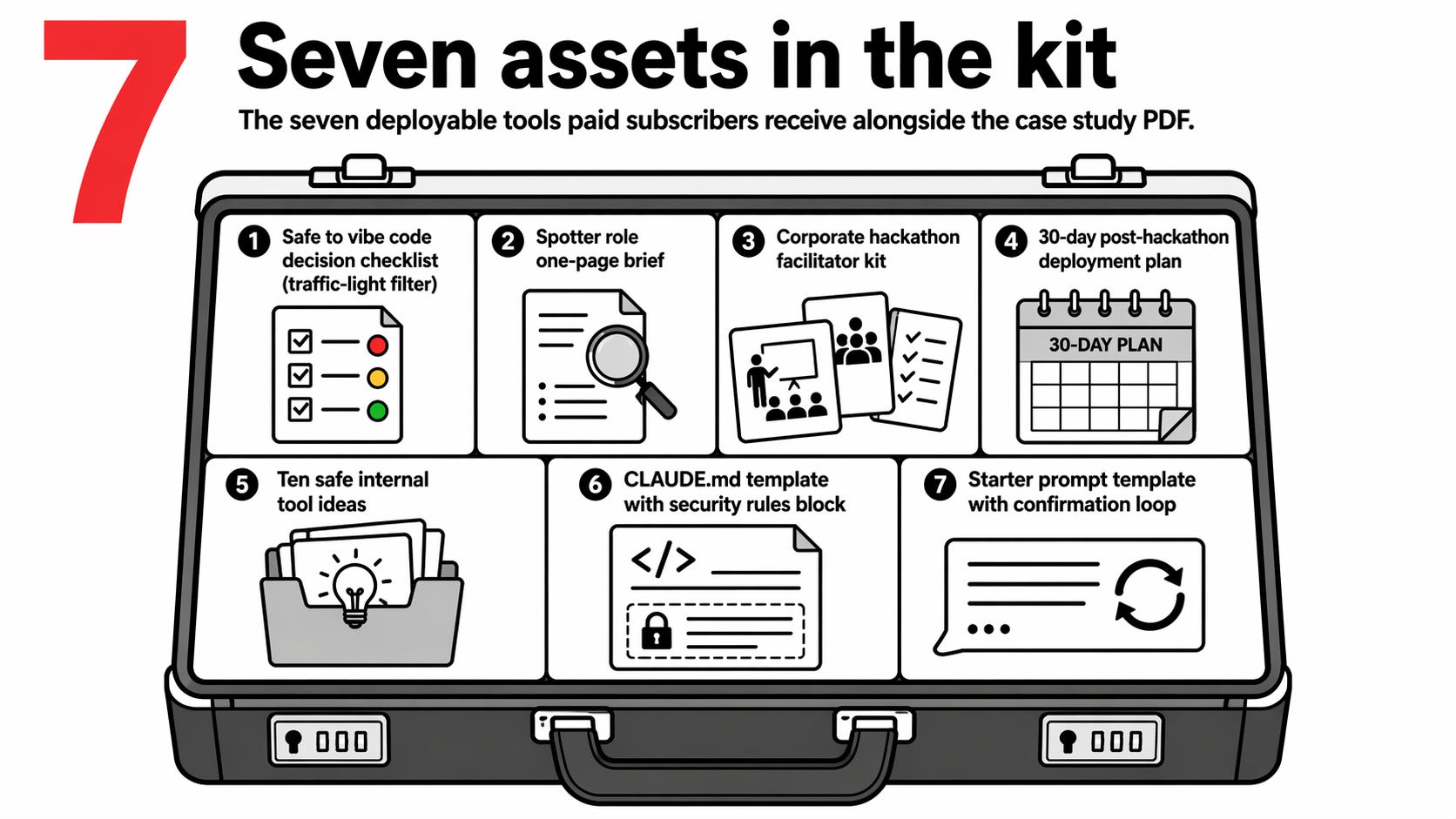
Paid subscribers get seven assets built to deploy without adaptation. A traffic-light decision checklist that filters any new vibe coding project before you write the first prompt. A one-page brief on the spotter role you hand to the reviewing developer. A facilitator’s kit for running a corporate hackathon where nobody has vibe coded before. A 30-day post-hackathon deployment plan. Ten bounded internal tool ideas your team can build safely. A CLAUDE.md template with the security rules block that cuts the most common failure modes. A starter prompt template with the confirmation loop that catches misfires before code is written.
If you are running a team, leading AI adoption, or planning a hackathon in the next quarter, the kit saves you weeks of building from scratch. Paid subscribers get the full thing at the companion post linked below.

The question worth answering tonight
Who in your company is currently not allowed to use Claude or Cursor on real work, who should be, and who is going to catch them the first time they ship something broken? If you cannot name all three people, the answer to “are we doing vibe coding” is no, whatever your procurement receipts say.
That is the work.
Adapt & Create,
Kamil




