

Upgrade to Paid and become the AI resource at work!
Most readers expense it to their employer;
AI education that turns you into a real asset to the org.
Hey Adopter,
On 7 May 2026, an engineer on the Claude Code team at Anthropic posted an essay declaring that HTML had replaced Markdown as the right default for AI-generated artifacts. He liked the density, the diagrams, the interactivity. He admitted HTML takes two to four times longer to generate. He admitted the diffs are noisy. He said he was, in his own words, far on the maximalist side of things. The post hit four million views inside a week

On 29 January 2026, Mintlify shipped the opposite default. Their head of product marketing wrote that documentation served to AI agents should be clean Markdown, not HTML. They reported a thirty times reduction in token usage. Cloudflare, three weeks later, measured the same thing on their own blog post and reported eighty percent fewer tokens when the same page was served as Markdown.
A token is the unit AI models use to count text. Roughly four characters of English in one token. Every word in, every word out, you pay per token.
Both sides are smart. Both report wins. The internet decided this was a methodology fight.
It wasn’t. It was two teams naming different constraints and choosing accordingly. The Anthropic engineer was optimising for cognitive density on his own review artefacts. He read his own output. He wanted it pretty. He accepted the cost. Mintlify was optimising for the token bill of the agents reading their docs, not the humans. Different constraint, different choice, no contradiction.
The fight on social media was held one level above where the decisions were made. People were picking a format. The two named players were picking a constraint and letting the format follow.
The actual disease
This is the dominant failure mode of AI adoption in 2026, and the format fight is just where it shows up most loudly.
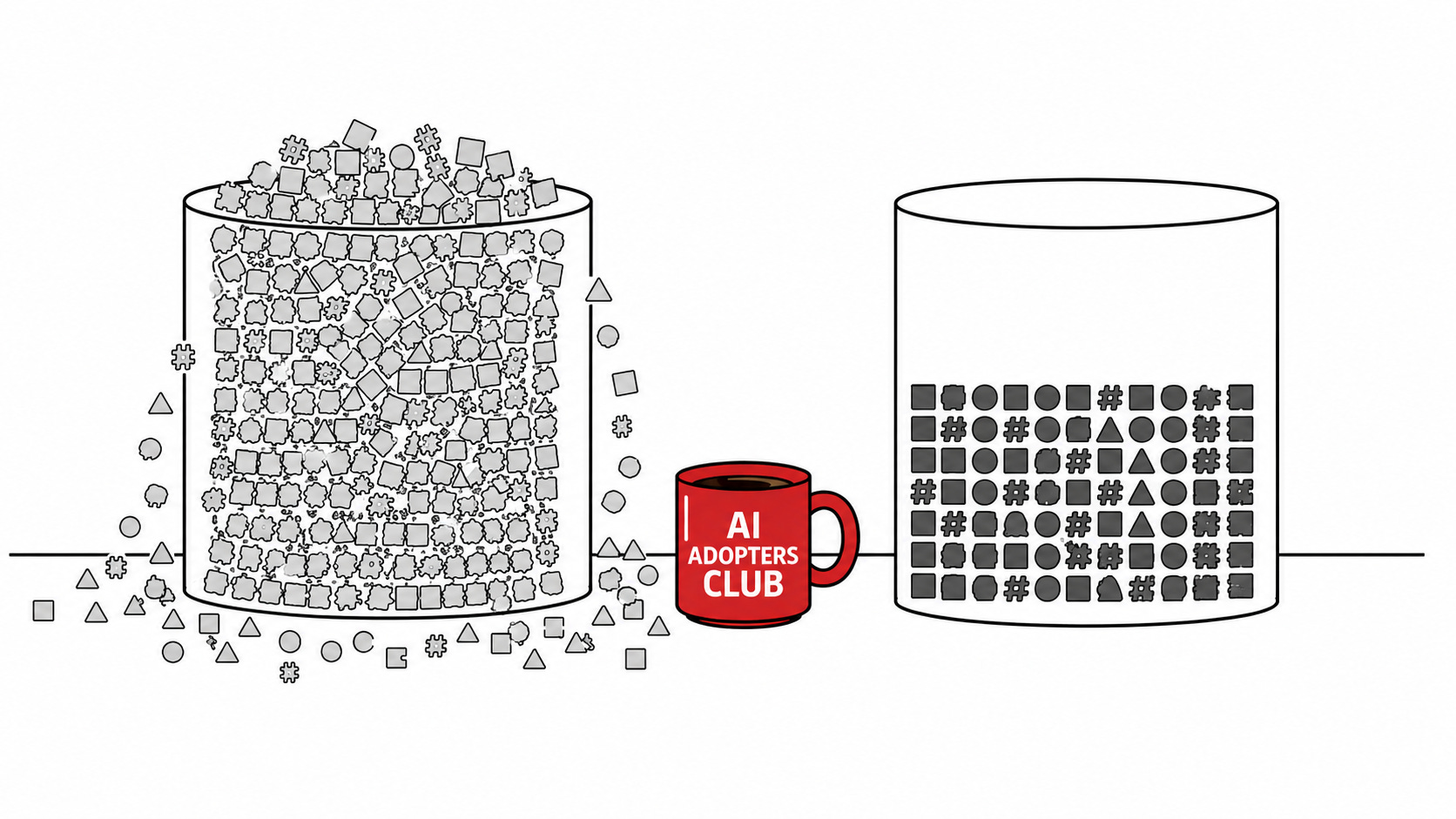
People default to maximum because the model supports it, then call it strategy. Bigger context windows. Richer output formats. More agents in the loop. More tokens through the pipe. None of it decided. All of it defaulted to, then defended as a methodology when someone questions it.
The context window is the maximum amount of text a model can read in one go. The bigger the window, the more you can stuff in. That doesn’t make stuffing it in a good idea.
The honest name for this is token maxing. It’s what happens when nobody at the table has named the constraint they’re optimising against, so the default becomes “use everything the model will let us use.” It feels like progress because the numbers go up. The window grows. The output gets richer. The agent gets more autonomous. The bill grows too, but slower than the demo wow factor, so nobody notices until the quarterly review.
An agent is an AI system that runs multiple steps automatically instead of waiting for you to prompt each one. More steps means more tokens. More tokens means more cost.
The opposing camp calls itself token budgeting and assumes it owns the moral high ground. Cheaper, leaner, more disciplined. But budgeters who refuse density without naming what density would buy them are making the same mistake in the opposite direction. They picked a number to minimise and called it a strategy. The thing they’re defending isn’t a position. It’s a vibe.
What the evidence says about defaulting
The case against thoughtless maxing isn’t ideological. It’s measured.
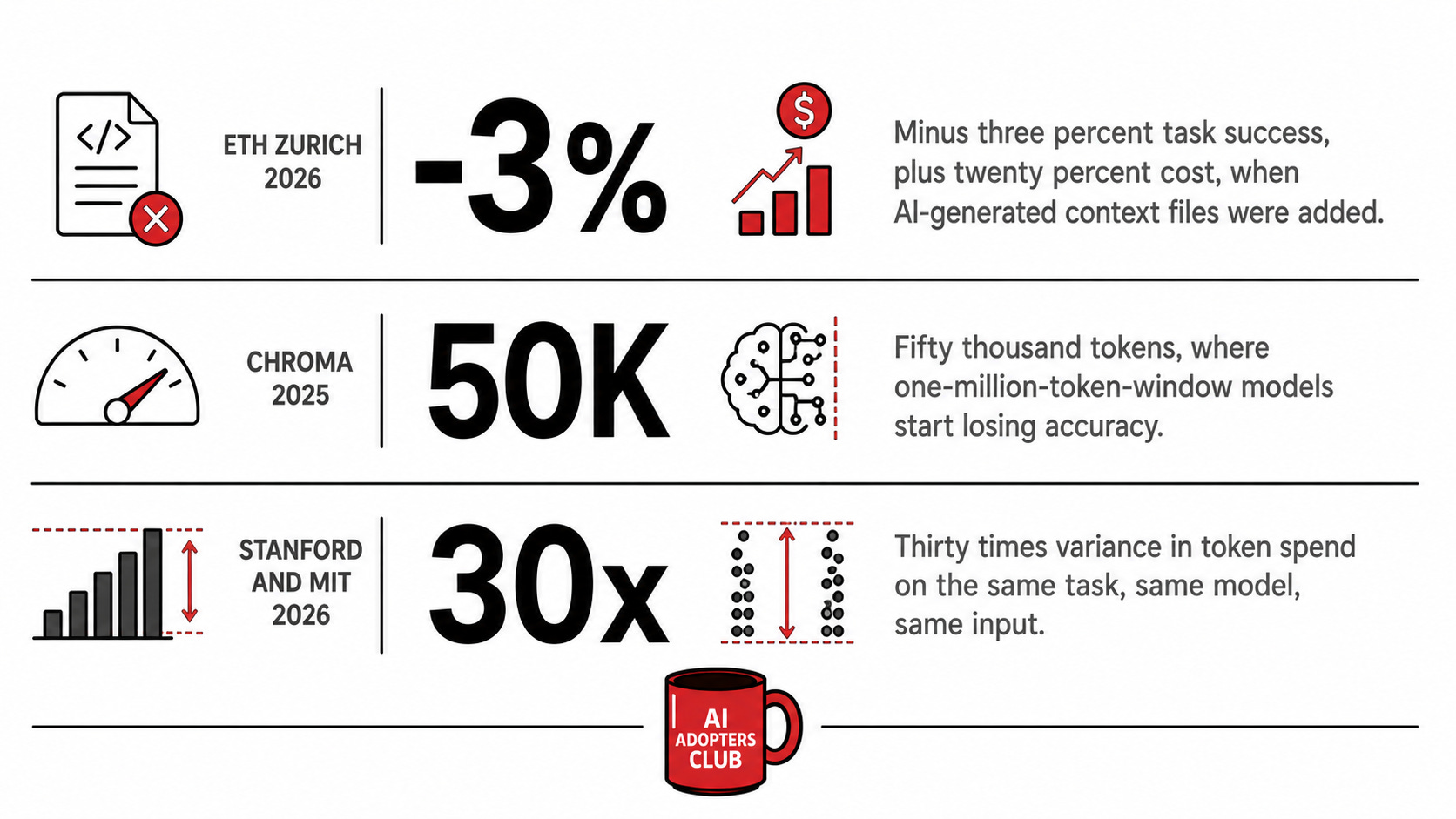
In April 2026, researchers from ETH Zurich’s SRI Lab published a study testing whether AGENTS.md files, the industry-standard practice of giving coding agents rich contextual instructions, actually helped. They ran 438 real-world coding tasks across Claude Code, Codex, and Qwen Code. The result was the opposite of what every operator in the field assumed. LLM-generated context files cut task success rates by three percent and raised costs by over twenty percent. Human-written ones added four percent on outcomes but still raised costs by nineteen percent. Their recommendation was that context files should describe only the minimum needed, and that LLM-generated ones should probably be omitted entirely.
AGENTS.md files are documentation files placed in code repositories to tell AI coding tools how the project works. The community treats them as best practice. The study tested whether they actually help.
Read that again. The most common advice in the agent-tooling community, followed religiously, was actively making things worse. Not in theory. In a peer-reviewed study, on real tasks, with named models.
The mechanism is what the Anthropic Applied AI team called context rot in September 2025. Every additional token in the window depletes what they call the model’s attention budget. Chroma tested eighteen frontier models in July 2025 and found that performance degrades at every length increment, not just near the limit. A model with a one million token window still rots at fifty thousand tokens. The window is real. The usable window is much smaller, and it shrinks as you fill it.
Bai et al. at Stanford and MIT published a paper in April 2026 with two findings that should end the maxing argument on their own. First, running the same agent on the same task produces up to thirty times variance in token spend. Same model, same input, same job, thirty times range on what it costs you to find out. Second, the models themselves systematically underestimate their own token usage, with prediction correlations no higher than 0.39. The models can’t predict what they’ll spend. The humans operating them definitely can’t.
Maxing in that environment isn’t ambitious. It’s flying blind and calling the lack of instruments a feature.
What budgeting actually means
Budgeting is the part most people get wrong. It isn’t austerity. It isn’t picking the smallest model and the leanest format and the shortest prompt. It’s the discipline of naming a primary constraint and letting the choice follow.
The Anthropic engineer named his constraint as cognitive density on artefacts he personally read. Given that constraint, HTML was correct. He budgeted, he just budgeted toward density instead of cost.
Mintlify named cost on the consuming agent. Markdown was correct. Same skill, different constraint.
Anthropic’s own multi-agent research system burns fifteen times more tokens than chat. They accepted that multiplier because they named breadth-first parallelism as their primary constraint. They didn’t default. They decided.
The teams that win at this aren’t picking between two formats or two modes. They’re answering one question before they start. What does this token spend actually buy me, and at what scale does that calculation flip? Once you can answer that, the format follows, the model follows, the agent shape follows, the budget follows. Without that answer, every choice is a vibe defended as a strategy.
The steel-man, on the record
The honest pushback to all of this is that budgeting is harder than maxing. It requires caching infrastructure most teams haven’t set up. It requires naming what stays static across requests, which most teams haven’t thought about. It requires measurement, which most teams aren’t doing. Telling the market to budget is telling it to do something it has no muscle for yet.
Caching means storing a stable prompt once so the model doesn’t pay full price to re-read it on every request. Anthropic, OpenAI, and Google all support it. Done well, it cuts input costs by up to ninety percent.
That objection is real, and it doesn’t change the answer.
Manual server deployments persisted for a decade after continuous integration existed. The reason wasn’t that CI was wrong. The reason was that the skill gap was real and the alternative shipped. Maxing is the manual deployment of 2026. It works. It ships. It also leaves money and reliability on the table that the operators who acquired the skill collect quietly while the rest argue about format defaults on Twitter.
The skill gap is the problem to solve, not the reason to abandon the position.
Budgeting is the right default. Maxing is what you reach for when you’ve named what budgeting would cost you and decided the trade is worth it. If you can’t name the trade in one sentence, you’re not maxing. You’re defaulting and dressing it up.
How to know which mode you’re actually in
Three tests, in order.
Can you name your primary constraint in one sentence? Not “we want it to be fast and good and cheap.” One constraint. Latency floor of two seconds. Cost ceiling of fifty cents per task. Accuracy floor of ninety-five percent on the eval set. If you can’t say it in one breath, the constraint doesn’t exist yet, which means whatever you’ve picked is a default.
Have you measured what your current default costs you? Not the per-token price. The per-task spend, the run-to-run variance, the cache hit rate, the format overhead. If those numbers are vibes, your strategy is a vibe.
What would you give up to relax the constraint by half? If you can’t answer, you don’t have a constraint. You have a preference.
The teams running these tests aren’t fighting about HTML versus Markdown. They’re fighting about whether their caching architecture is set up to make the format question irrelevant, whether their retrieval is tight enough that context rot stops mattering, whether their agent loops have a stop condition that catches the runaway run before it costs them four figures.
Retrieval means pulling only the right snippets of information from a larger store and feeding them to the model, instead of giving it everything and hoping it finds the right bit.
The format wars get attention because they’re visible. The real work is invisible. That’s the actual gap between operators who are winning at this and operators who are still arguing about defaults.
Token maxing is what you do when you can’t budget. Token budgeting is what happens when you can answer one question.
The skill is the question, not the answer.
Adapt & Create,
Kamil




