
The Llama 4 Reality Check
What Meta's AI Release Actually Means for Your Implementation Strategy


Hey Adopter,
Mark Zuckerberg recently unveiled Meta's latest AI offering, Llama 4, at LlamaCon on April 29. While the announcement came with ambitious claims and a reported billion-user reach, the community reception tells a more nuanced story. Let's cut through the marketing to understand what practical lessons we can extract from both Meta's strategy and the technical reality.
In my own advisory work, the teams that move fastest don't build the biggest models. Instead, they build the smallest ones that solve something annoying. This principle is worth considering as we examine Meta's approach against the actual community reception.
The Mixed Reception Reality
Meta's Llama 4 introduces what Zuckerberg calls a "herd" of specialized models:
"Scout and Maverick are good. They have some of the highest intelligence per cost you can get of any model out there. They're natively multimodal, very efficient, run on one host," Zuckerberg claimed during the LlamaCon keynote.
They sound like rejected Top Gun call signs, but community reaction has been decidedly mixed. Multiple sources indicate significant disappointment with Llama 4's performance relative to expectations. One viral Reddit post with 520 upvotes expressed being "incredibly disappointed with Llama-4," describing test outcomes as "simply atrocious." AI researcher Simon Willison summarized the community sentiment as "decidedly mid."
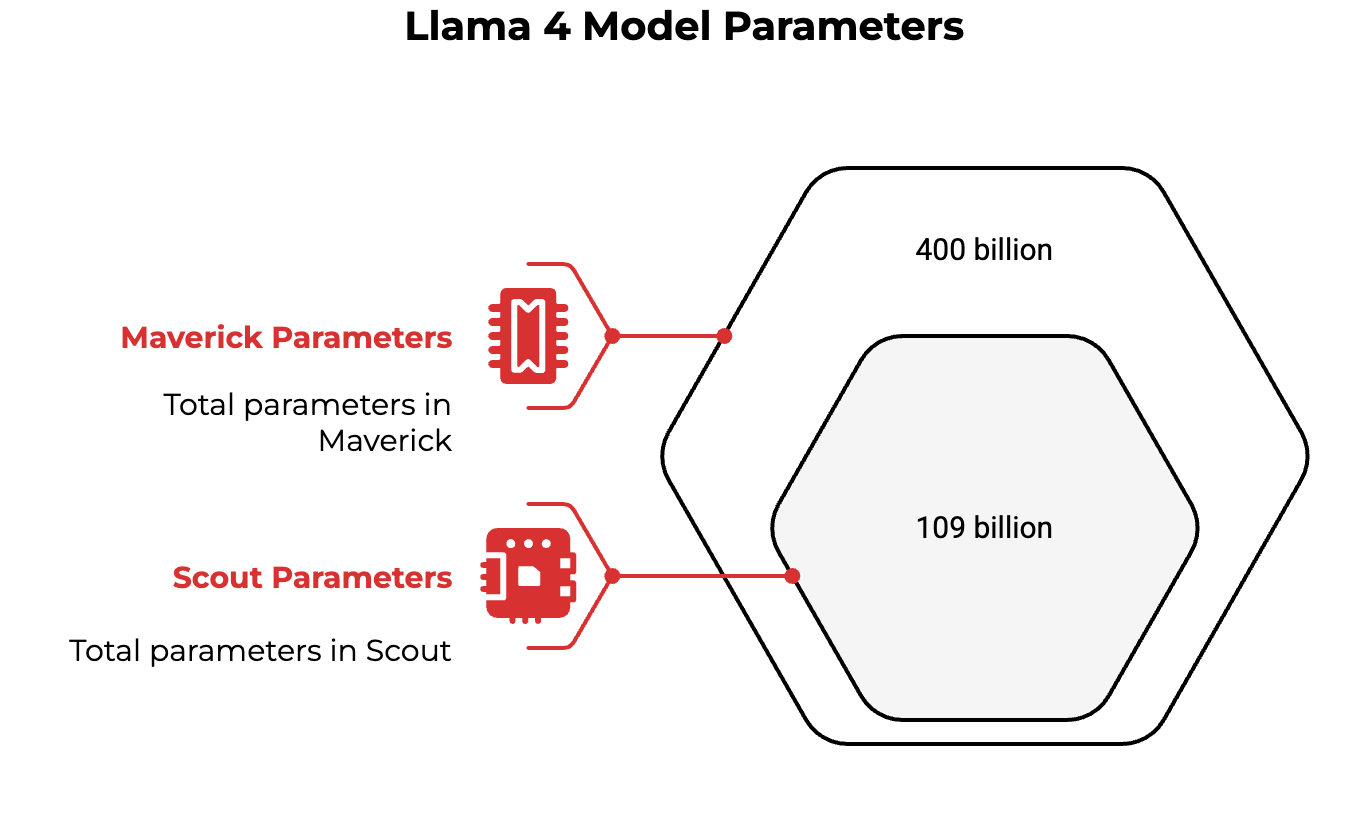
Llama 4 Scout features 109 billion total parameters (with 17 billion active) through a mixture-of-experts architecture. The more powerful Maverick contains 400 billion total parameters. Yet despite the impressive specifications, performance testing indicates that "Llama-4-Maverick model... performs similarly to Qwen-QwQ-32B when it comes to coding tasks" despite having significantly more parameters.
Adopter's Take:
The real lesson here isn't that you need a billion users or 400B parameters. It's that integration beats invention. Many organizations fall into the trap of chasing parameter counts while ignoring whether the model actually performs well on their specific use cases. Always benchmark against your particular needs rather than trusting marketing claims.
The Benchmark Controversy
A significant controversy emerged after release when it was revealed that "Meta submitted a special, non-public 'experimental' version of Maverick" for the popular LMArena leaderboard rather than the actual released model. This "initial opacity drove community blowback" and led to LMArena banning such specially tuned models.
This gap between benchmarked performance and real-world capabilities highlights a critical lesson for organizations: Beware of leaderboard engineering. The models that top benchmarks aren't always the ones that deliver in production environments.
Integration Strategy That Works
What separates Meta from most organizations isn't just model development but actual deployment. Their AI is integrated where people already spend time: Instagram, Facebook, WhatsApp. This creates native adoption rather than forcing new user behaviors.
"We made the Llama Scout and Maverick models certain sizes for a specific reason. They fit on a host and we wanted certain latency, especially for the voice models that we're working on, that we want to pervade everything we're doing from the glasses to all of our apps," Zuckerberg noted in his recent interview.
This integration-first mindset offers a valuable lesson for any organization. Instead of creating standalone AI projects that require users to change behavior, Meta embeds AI into existing workflows where people already operate comfortably.
I've seen leaders obsess over dashboards while ignoring the one metric that actually matters: whether people use the thing. Meta's approach reinforces this principle at unprecedented scale.
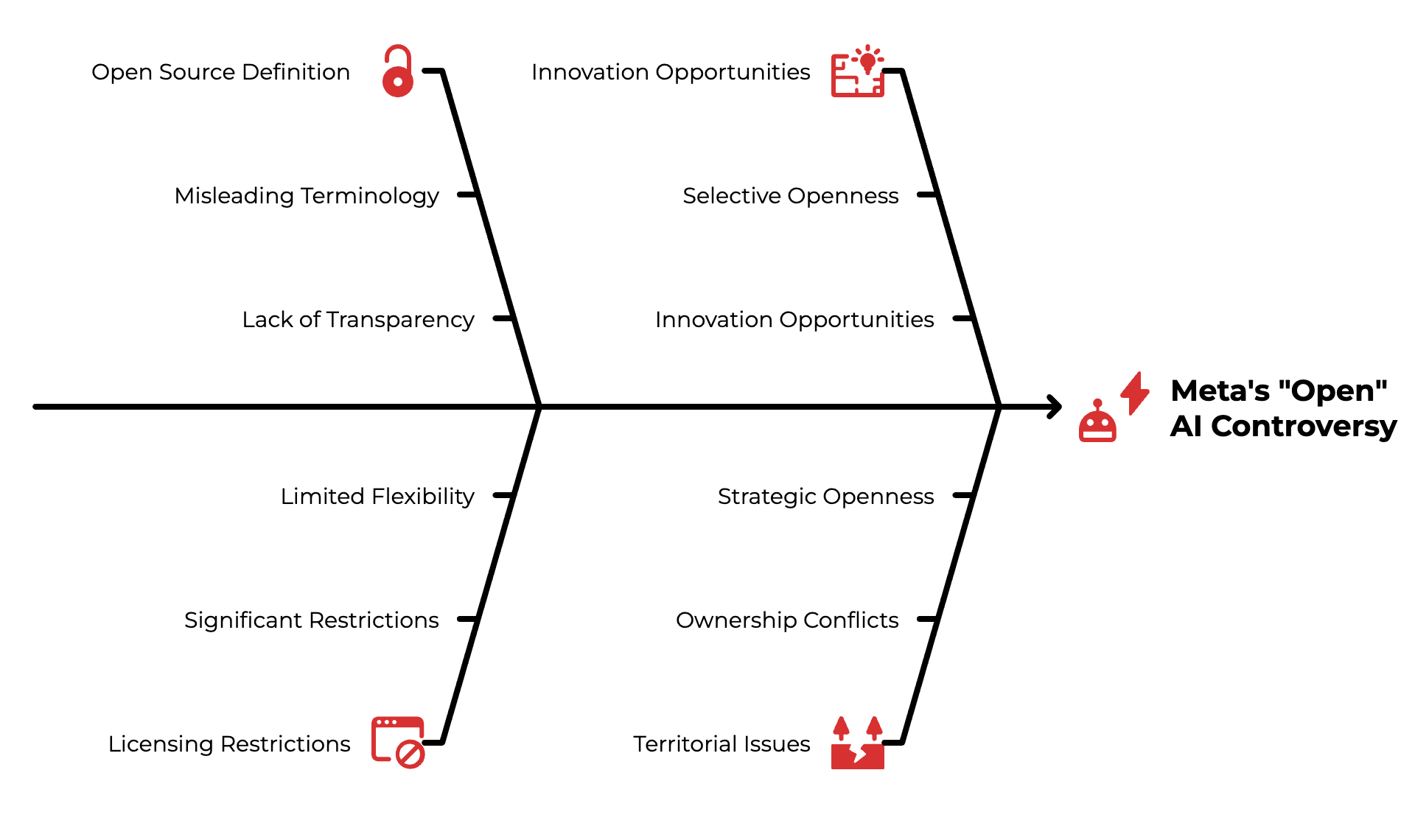
The "Open Source" Reality
Meta continues promoting an open approach to AI development. "We continue to believe that openness drives innovation and is good for developers, good for Meta, and good for the world," Zuckerberg stated.
However, Meta has faced criticism from the Open Source Initiative for potentially misleading terminology. The OSI has accused Meta of "polluting the concept of open-source technology" by using the term for models that don't provide the full transparency or flexibility of true open-source software.
While the models are available on platforms including Amazon Bedrock and Cloudflare Workers AI, the licensing contains significant restrictions that prevent truly open use.
Adopter's Take:
In my work with resource-constrained teams, the common failure isn't technical but territorial. The companies making real progress aren't trying to own everything; they're strategic about which doors to open and which to keep closed. Despite the licensing controversy, Meta's selective openness does create innovation opportunities that completely closed models don't offer.
Leadership Instability Behind the Scenes
The rosy picture painted at LlamaCon obscures significant organizational turbulence. Reports indicate "Serious issues in Llama 4 training" coincided with the resignation of Meta's VP of AI. Some community members speculate this departure might be "an attempt to evade accountability for the company's lagging progress."
This leadership instability suggests potential internal problems with Meta's AI development that contradict the narrative of smooth execution and strategic clarity.
Areas of Genuine Value
Despite the controversies, Meta's AI security initiatives have received positive attention in the community. The recently launched "LlamaFirewall" framework designed to secure AI systems against emerging cyber risks represents a valuable contribution. Similarly, "Llama Guard 3-1B-INT4" has been recognized for achieving "comparable or superior safety moderation scores to its larger counterpart... despite being approximately 7 times smaller."
Some engineers might take the challenges as a sign to abandon Llama models. Others will extract the valuable components while maintaining realistic expectations. Guess which team wins?
The Relationship Revolution Claims
Zuckerberg's observation about AI relationships represents an area where vision exceeds current capabilities:
"Already people have meaningful relationships with AI therapists, AI friends, maybe more. This is just going to get more intense as these AIs become more sophisticated," he stated in his discussion about AI's future.
While the vision is compelling, current Llama 4 models likely lack the performance consistency needed to deliver on this promise. The gap between Meta's aspirational vision and actual model capabilities remains substantial.
Adopter's Take:
The metrics we use to evaluate AI need a complete overhaul. In my advisory work, I've watched teams celebrate accuracy improvements that users never notice while ignoring the emotional response that determines whether people come back. The relationship quality concept has merit, even if current implementations fall short.
At AI Adopters Club, we cut through the noise to spotlight what's working right now, not in theory, but in the messy trenches of work. Here's what I'd be prioritizing based on a balanced assessment of Llama 4:
Practical Principles Worth Implementing
Benchmark against your specific needs. Rather than trusting leaderboard positions or marketing claims, test models on your actual use cases. The results often contradict public benchmarks.
Integrate with existing behaviors. Build AI into workflows people already use rather than creating separate destinations requiring new behaviors. Meta's integration strategy across their platforms demonstrates this approach.
Consider selective openness. Open-source claims aside, creating conditions where partners and developers can extend your capabilities has merit. Just be transparent about limitations.
Security first. Meta's work on LlamaFirewall and Llama Guard shows that even with model performance challenges, security innovations can deliver real value.
Look beyond the hype. The gap between public announcements and community reception reveals that critical assessment is essential before committing to any AI strategy.
The most important insight from Meta's release isn't about technical specs but about the importance of testing claims against reality. The organizations creating a measurable advantage will be those that apply critical thinking to separate genuine innovation from marketing polish.
We're already seeing how Llama 4 reshapes expectations around latency, cost, and interface. But the real play? It's what happens when AI claims meet community verification. More on that soon.
Adapt & Create,
Kamil