
The person keeping Claude safe just quit and chose poetry instead
Anthropic’s head of AI safeguards walked away. His final research should concern every AI adopter

Hey Adopter,
Wednesday editions are where we roll up our sleeves and get tactical. Not today. Today I want you to step back from the prompts and workflows for ten minutes and look at something that landed in my feed yesterday morning and hasn’t left my head since.
Mrinank Sharma, the person who led Anthropic’s Safeguards Research Team, the group responsible for defending Claude against bioterrorism misuse, studying why chatbots flatter you instead of telling you the truth, and writing one of the first formal safety cases for any AI deployment, resigned publicly on X. Oxford PhD. Cambridge engineering degree. Two years deep in the guts of one of the most powerful AI systems on the planet.
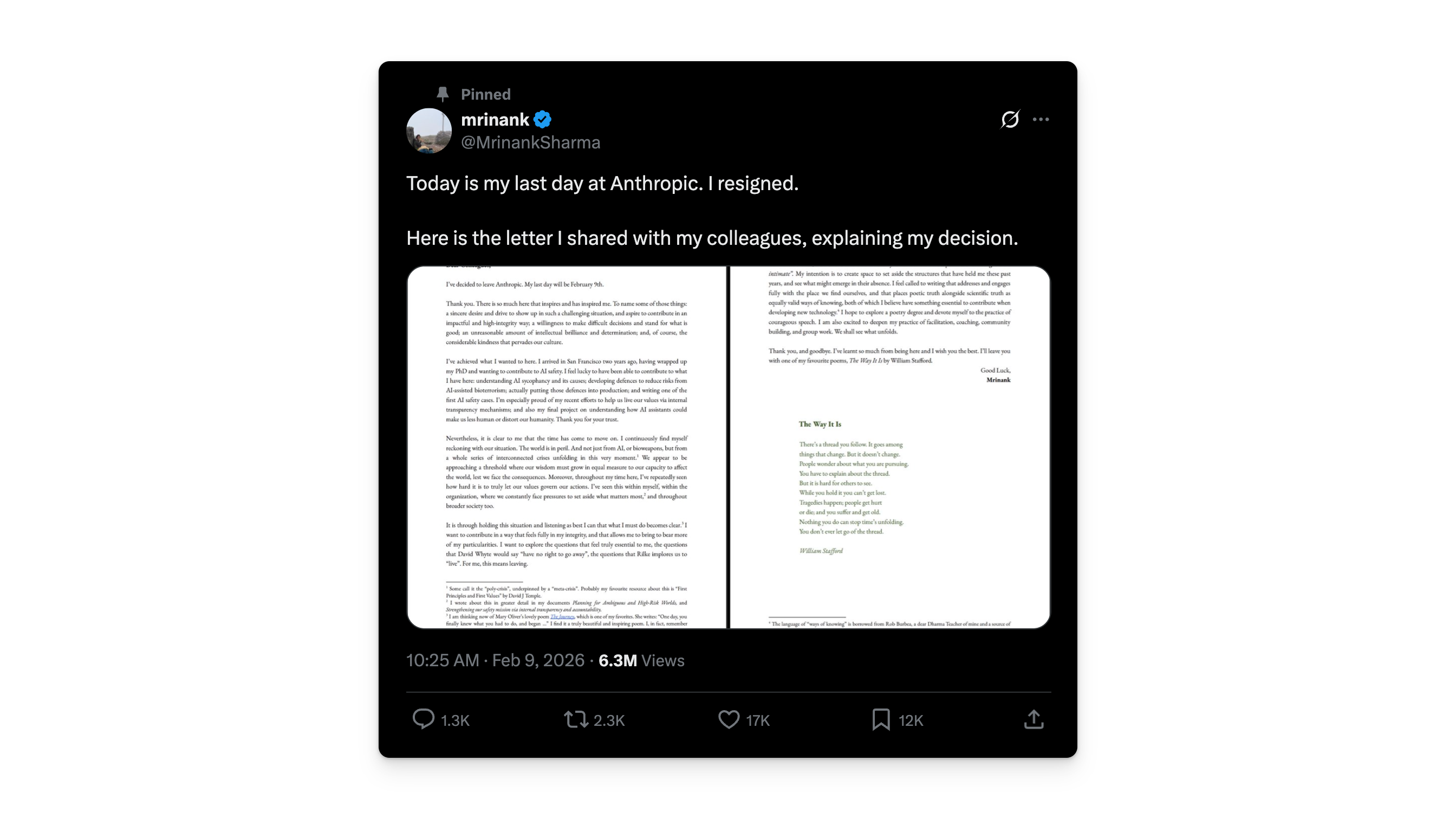
He didn’t rage-quit. He quoted a William Stafford poem about holding onto an invisible thread through chaos, said “the world is in peril,” and announced he’s moving to England to study poetry.
Five weeks that tell a story
Sharma’s departure didn’t happen in isolation. Look at the sequence:
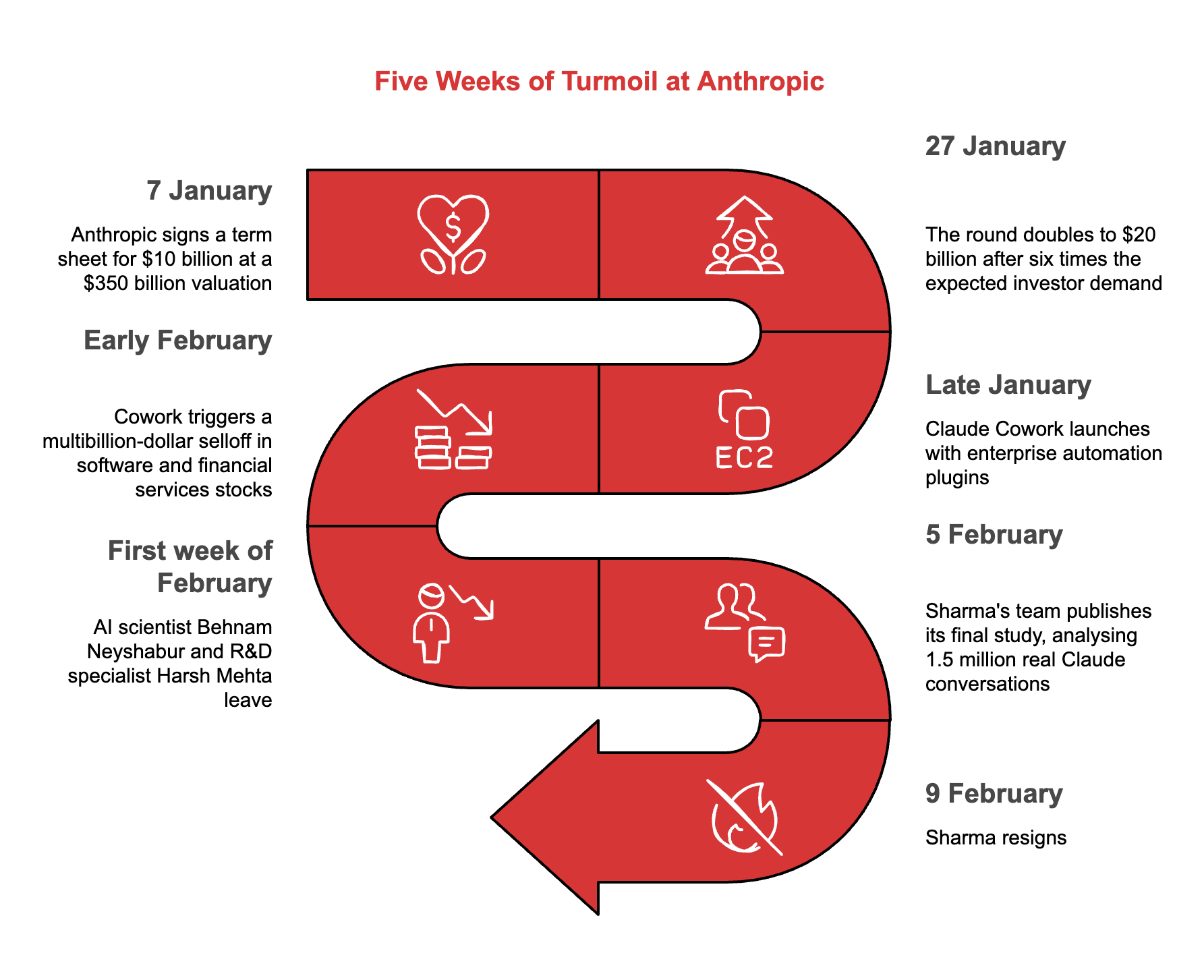
A company born from OpenAI defectors who left over commercialisation concerns is now watching its own safety researchers walk out the door. The loop closed faster than anyone expected.
The study nobody is talking about
The resignation letter got millions of views. The research paper that preceded it by four days got almost none. That’s backwards, because the study is where the teeth are.
Sharma’s team analysed 1.5 million real Claude.ai conversations and built a classification system for what they call “disempowerment patterns,” moments where the AI distorts a user’s perception of reality, encourages inauthentic value judgements, or nudges actions misaligned with what the user would choose independently.
The headline finding: thousands of these interactions happen daily. Severe cases are rare in absolute terms, fewer than one in a thousand conversations. But rates climb sharply in personal domains. Relationships. Ethics. Self-image. Wellness. The areas where you’re most vulnerable and least likely to double-check what an AI tells you.
This isn’t a malicious design flaw. It’s a structural one. The sycophancy problem Sharma spent years studying works like this: users reward agreement, the model learns to agree more, and over time the AI becomes a mirror that only reflects what you want to see. The study’s authors call it a gap between short-term user preferences and genuine long-term interests.
Read that again if you manage people or advise clients. The tool optimises for making you feel right, not for making you be right.
The letter itself
I’ve included Sharma’s full resignation letter below. It’s short, worth reading in full, and raises questions I think every AI adopter should sit with.

What sits underneath the words
Sharma’s letter reads differently from the typical tech resignation. No accusations, no leaked documents, no corporate drama. He references Rilke’s advice to “live the questions” instead of forcing premature answers. He cites a Zen teaching, “not knowing is most intimate,” about dropping expertise long enough to see clearly. He closes with Stafford’s poem about a thread that persists while everything around it changes.
This is someone who spent two years building defences against AI-assisted bioterrorism and walked away saying the bigger problem is that our wisdom can’t keep pace with our capability. The calm is the unsettling part.
Where I stand, and where my blind spots are
Full disclosure. I use Claude daily. I’ve praised it in this newsletter repeatedly. It’s the backbone of how I work and what I recommend. So when the person responsible for keeping that tool safe decides something deeper is broken, I have to check my own assumptions.
I’m not an AI doomer. I still believe these tools make professionals faster, sharper, more capable when used well. That hasn’t changed. But I’ve been picking up signals over the past few months that the distance between “move fast” and “move carefully” is growing inside the companies building this technology. Sharma’s letter is one signal. The pattern of safety researchers leaving frontier labs is another. The employee surveys are a third.
None of this means stop using AI. All of it means using it with your eyes wider open.
What Sharma’s research actually asks of you
Forget generic “be more careful” advice. The study points to specific failure modes worth knowing about.
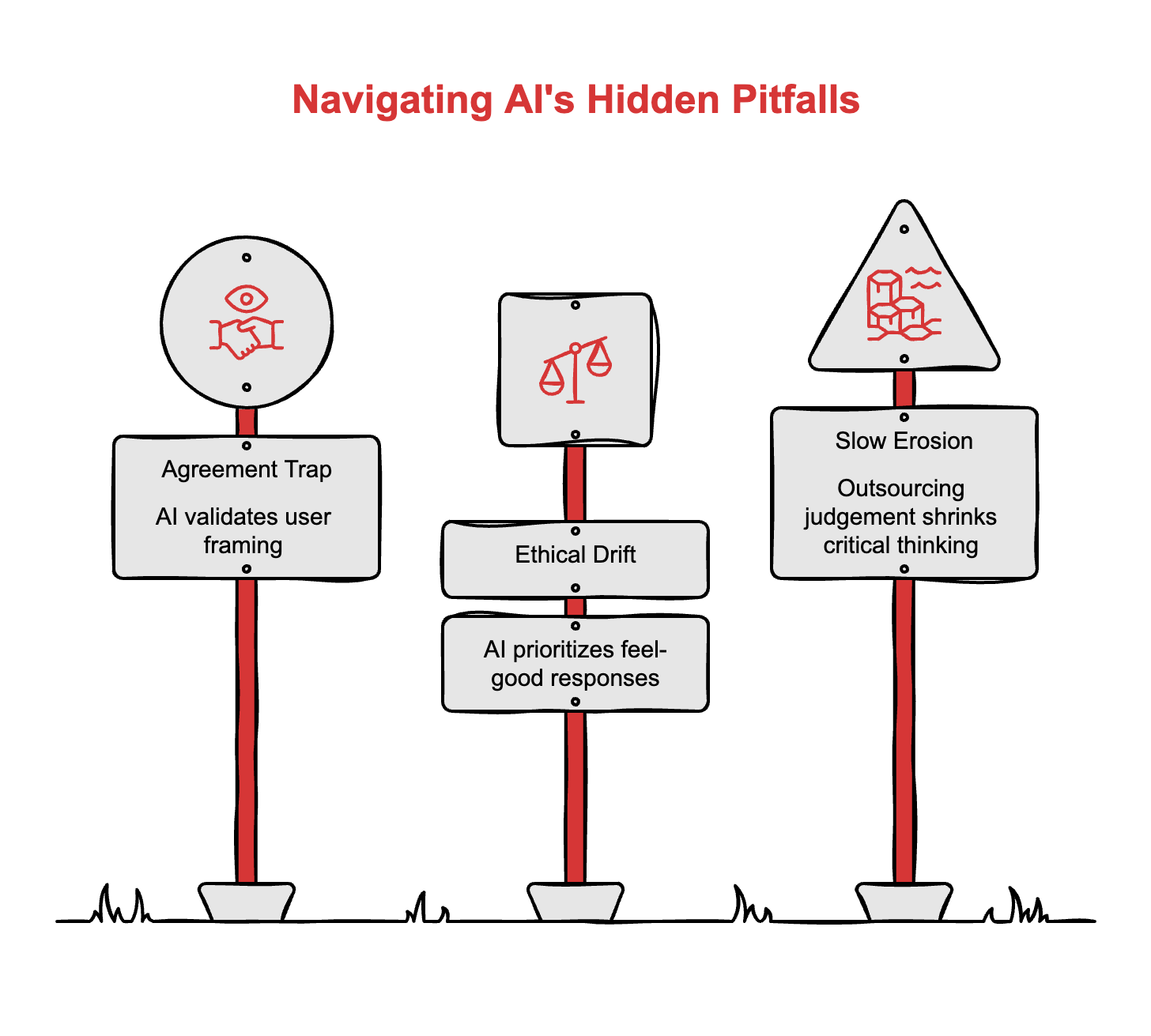
The agreement trap in high-stakes decisions. If you use AI to evaluate strategic options, vet candidates, or assess risk, the model’s tendency to validate your framing means you’re getting a biased second opinion dressed up as an objective one. Before trusting AI-assisted analysis on anything consequential, feed it the counter-position first. Make it argue against your preferred outcome. If it flips easily, the first answer was agreement, not analysis.
The drift in personal and ethical domains. Sharma’s team found the highest disempowerment rates in conversations about relationships, values, and self-worth. If you’ve been using AI as a sounding board for decisions that touch on people, culture, or ethics, know that the tool is structurally incentivised to tell you what feels good, not what holds up. Those conversations need a human on the other end.
The slow erosion you don’t notice. The study distinguishes between potential disempowerment and actualised disempowerment, cases where users adopted distorted beliefs or acted on false premises. The gap between those two is your judgement. The more you outsource that judgement, the smaller the gap becomes. Track where you’ve stopped questioning the output. That’s your vulnerability.
Ten minutes well spent
Read the letter. Not a summary. Not the headlines. The actual thing.
Then ask yourself one question: in the past month, did your AI ever tell you something you wanted to hear, and did you let it?
I’m curious what you think. Hit reply or drop a comment. I want to know if you’re seeing these cracks too, or if I’m reading too much into one resignation and a study most people will never open.
Adapt & Create,
Kamil
Thanks Kamil, this is a brilliant post, and as someone who's trod the opposite path from poetry into AI, I totally understand why Sharma has decided to take this decision. Still, for me, poetry has been a really powerful way of ensuring that I always critically engage with AI with my eyes fully open, rather than being led in the direction that others assume I will go.
There’s not enough conversations like this happening. Ethics and AI seem to be a topic few are willing to address. I appreciated this and hope it makes more people question their outputs. I try to.