
No, Data Centers Aren't Draining the Rivers. But Your Town Might Be Next.
No study shows destruction. But one facility can be 40 percent of a small town's water. Both are true, and the difference is everything.


TL;DR: AI data centers can create a serious local water burden, but not a civilizational water crisis.
No peer-reviewed study, USGS report, or EPA record attributes aquifer collapse or permanent water-source destruction primarily to data centers. Nationally, they are a rounding error: well under 1% of US public water supply, versus agriculture’s roughly 42% of US freshwater use.
Locally, the impact is real. In The Dalles, Oregon, Google uses roughly 40% of the city’s water. In Newton County, Georgia, Meta’s facility uses about 10% of county supply. A single large facility can reach 5–20% or more of a small town’s peak capacity.
On pollution, the scariest images are mostly noise: many viral dirty-water pictures are AI-generated fakes or misattributed construction impacts. No operating data center has been shown to be the primary cause of water-source contamination.
The right frame is siting and cooling, not apocalypse. This is a problem of where facilities are built and how they are cooled, not proof that AI is “draining the rivers.”
Hi Adopter,
In The Dalles, Oregon, a city of about sixteen thousand people, one company now uses close to forty percent of the municipal water. The company is Google, the water cools its data centers, and the city spent two years in court, on Google’s side, fighting to keep the figure secret as a trade secret. They lost. The records came out. The number was real.
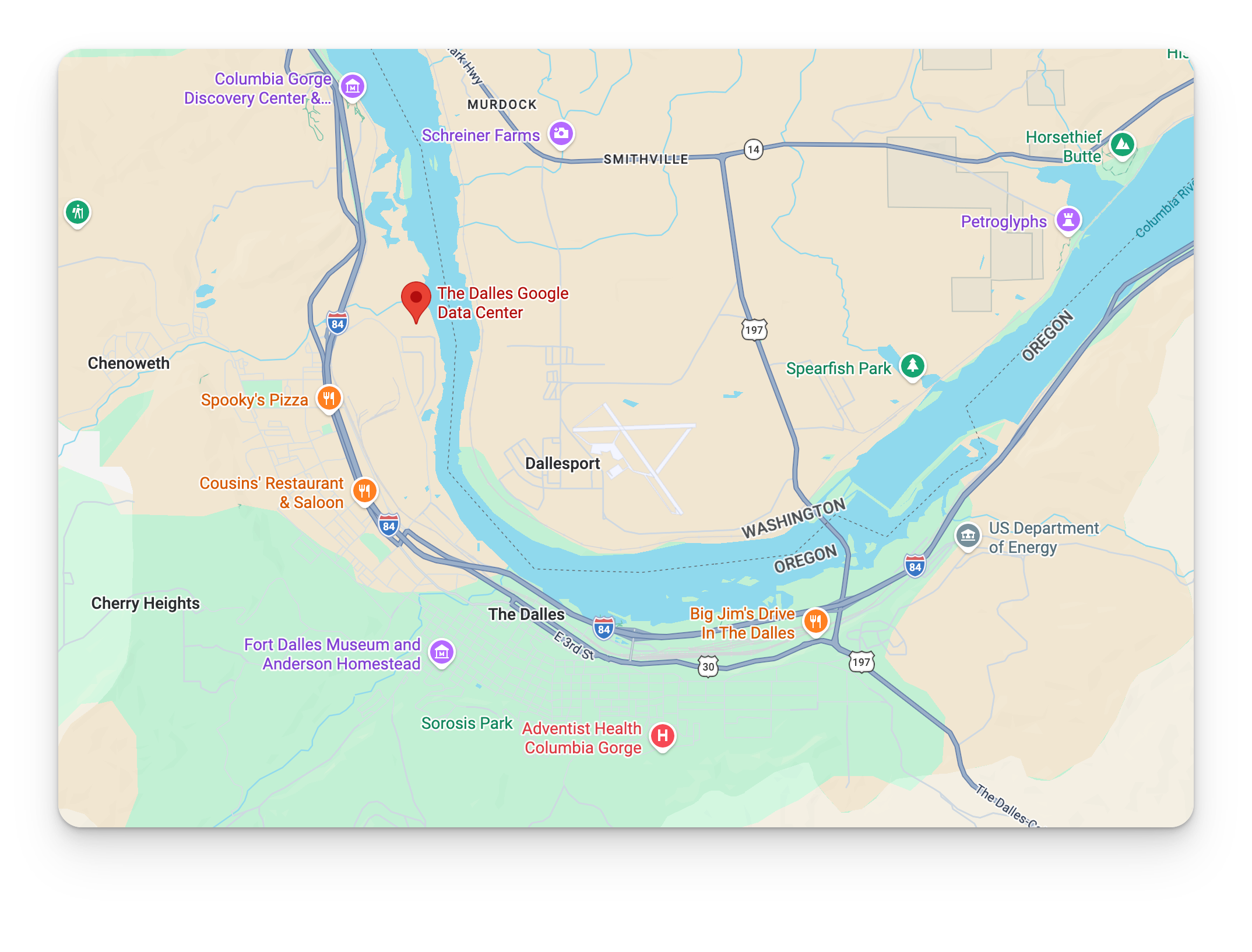
If you have read that a data center is draining your region dry, The Dalles is why that story exists. The fear is not invented. In specific places, a single building really can take a city-sized share of the water, and the AI boom is adding these buildings fast.
So take the worry seriously. Then ask the question that actually matters, because the honest answer splits cleanly in two, and almost every headline you have seen blurs the split.
Whats your opinion on AI data centers?
Two questions wearing one costume
Are AI data centers destroying local water sources, collapsing aquifers, ruining supplies for good? No. Not anywhere that science has documented. After an exhaustive search of peer-reviewed journals, USGS groundwater monitoring, and EPA records, there is no study that pins aquifer collapse or permanent water-source destruction primarily on data centers. The most comprehensive global groundwater survey ever done, 170,000 wells across 1,693 aquifers, names irrigation as the driver of decline and does not mention data centers at all.
Are AI data centers creating real, growing, locally concentrated water stress in the wrong places? Yes. The Dalles is not a fluke. In Newton County, Georgia, Meta’s facility uses about ten percent of the county’s water. In Loudoun County, Virginia, data centers use roughly the same share. And a 2026 study found a single facility can equal five to twenty percent or more of a small town’s peak water capacity.
Both are true. The whole topic lives in the distance between “destruction” and “burden,” and the people shouting from each end are both selling you the wrong word. One side says aquifers are being murdered. The other says it is less than one percent nationally, so relax. They are answering different questions, and you can hold both answers at once.
The trick is three distinctions. Get them straight and the panic resolves into something far more useful: a real, manageable, local problem about where these things get built and how they get cooled.

Distinction one. Taken back, or gone for good.
Withdrawal is water you take from a source. Consumption is water you take and never give back, because it evaporated. These are not the same number, and the gap between them is enormous.
A power plant is the clean example. US thermoelectric plants withdrew about 103 billion gallons a day in 2015 but consumed only about 2.7 billion. A thirty-eight to one ratio. The cooling water runs through and goes right back to the river, a little warmer. Withdrawal looks terrifying. The actual loss is small.
Data centers are the opposite shape. They withdraw less, but they evaporate around seventy-five percent of what they take, against roughly twelve percent for a normal household. So a data center punches well above its weight on the number that actually matters, which is consumption, the water that is genuinely gone from the local system.
Here is how this gets weaponized. An advocate quotes a giant withdrawal figure for one thing and a small use figure for another, and the comparison is rigged because they are different metrics. Whenever you see a scary water number, ask first: is this withdrawal, or is it consumption? Depletion only tracks the second one.

Distinction two. The water you see, and the water you don’t.
Direct water is what steams off the cooling towers at the data center. Indirect water is what evaporated at the power plant making the electricity that data center runs on. The indirect number is almost always missing from the headline, and it is usually the bigger one.
Federal analysts put US data centers’ direct water at about 66 billion liters in 2023, and the indirect water at around 800 billion. Roughly twelve to one. Now the honest caveat, because impartial means showing the soft spots in your own favorite stat: that twelve-to-one leans on counting evaporation from hydroelectric reservoirs, water that would largely evaporate anyway. Strip the hydropower out and the ratio falls to something like three or four to one. Either way, the invisible number beats the visible one.
The implication is the useful part. A data center’s single biggest water lever is often not its cooling tower at all. It is which power grid it plugs into. The same building draws a very different indirect footprint on a hydro-heavy Northwest grid than on a gas-heavy Texas one. The water decision hides in the energy decision.

Distinction three. The rounding error that is also forty percent.
Nationally, data centers are a rounding error. Direct consumption is well under one percent of US public water supply and about two hundredths of one percent of total freshwater use. Agriculture is roughly forty-two percent of US freshwater withdrawals and the dominant consumer by far. Next to a farm, a data center is a teaspoon next to a swimming pool.
And yet. A national average is exactly the wrong tool for a local resource. The water in The Dalles does not know that data centers are tiny nationally. It only knows that one customer now takes forty percent of it. A single facility pulling eight million gallons a day against a county’s peak capacity is a real local concentration problem while being completely invisible on a national chart.
So both errors are common, and both are wrong. The aggregate “it’s less than one percent” cannot wave away a town where it is forty. A dramatic local number cannot be stretched into a national crisis. Water is local. Judge it locally.

The national scoreboard, since you should see it once
US data centers directly consumed 17.4 billion gallons of water in 2023, about the yearly water of 160,000 households, up roughly threefold since 2014. Hyperscale and colocation sites are 84 percent of it. By 2028 the total US projection runs 38 to 73 billion gallons depending on how fast AI grows and how teams cool it.
That last point matters more than it sounds, and it is where most coverage, including the version of this story I started with, gets the scope wrong. The widely shared “60 to 124 billion liter” 2028 figure is the hyperscale-only slice, not the national total. Quote it as the whole and you understate the high end by more than double. Precision is not pedantry here. It is the difference between informing people and scaring them with the wrong denominator.
Why the scariest number you’ve seen is probably wrong
You have likely seen “ChatGPT drinks 500 milliliters of water per query.” It is one of the most-shared stats of the AI era, and it is a misread. The original research found about 16.9 milliliters per medium response, and even that was for an older GPT-3 model, counting evaporation, not a glass of water poured down a drain. The “500 milliliters” was the figure for ten to fifty responses. The media compressed the range into “per query” and landed one to two orders of magnitude off.
This is the pattern under the whole panic. Real underlying data, then a compression or a conflation, then a number that is technically traceable to a paper and still wildly misleading. It does not mean the concern is fake. It means you cannot take any single viral figure at face value, from either direction.
And it is not only numbers that get manufactured. The water panic now has its own genre of fake image. The grimy water towers captioned “you can’t drink data” that show up under every data center story are AI-generated, rated false by fact-checkers. So is the claim that Zuckerberg dried up the Rio Grande. There is essentially one set of real dirty-water photos in wide circulation, brown jars from a town in Georgia, and even that story turns out to be more about a construction site than a cooling system. The full answer to whether anyone is poisoning the water is below. The short version: mostly no, with a couple of genuine caveats and a lot of synthetic noise.
Below, the part that turns this from a clever explainer into something you can actually use:
The causality question in full, and exactly why “destruction” fails even though the worry is legitimate
Whether the water is actually being polluted, what those brown-water photos in your feed really are, and which ones are AI-generated
All five case studies, graded, from real-stress to genuinely-fine, including the one your fears probably attached to
Whether “water-positive by 2030” means anything (it does not, in the way you think)
The three questions that let you read any water headline in ten seconds and know who is playing you
INSERT SUBSTACK PAYWALL HERE

The causality question, stated honestly
The strong claim deserves a precise answer, not a dismissive one.
Searched across peer-reviewed journals, USGS publications, EPA enforcement records, and state water-district reports, there is no study that causally attributes aquifer collapse, permanent recharge loss, or contamination-to-unusability primarily to data center operations. That absence is itself the finding. The North Phoenix aquifer study, in the most data-center-dense Western market, documents real storage decline at 89 of 102 monitoring stations and attributes it to reduced recharge and outflow, finds no land subsidence, and never mentions data centers.
The strongest real-world harm case is Amazon’s, in Boardman, Oregon, where a nitrate settlement reached $20.5 million in 2026. But Oregon designated that basin a groundwater problem area in 1990, about twenty-one years before Amazon’s first local facility, and the nitrate came from decades of agriculture. The alleged data center role is concentrating a pre-existing farm pollutant, a secondary contribution to an old problem, settled with no admission. It is the best “harm” case there is, and it still does not reach destruction.
Now the part that keeps this impartial rather than smug. “No evidence of destruction” is not the same as “proven safe.” Operators rarely disclose facility-level water use, and USGS does not even track data centers as a category, so the long-term, before-and-after monitoring that could definitively settle it mostly does not exist. The strong claim is unsupported, not disproven. The transparency gap is real, and it is its own finding.

And what about pollution? Are they dirtying the water?
That whole section was about quantity, about water running low. The other fear, the one driving the photos in your feed, is about quality. Different question, and it deserves a straight answer.
Short answer: mostly no, and it is the most misunderstood corner of the debate. As of mid-2026 there is no peer-reviewed study, no EPA enforcement action, and no court ruling that an operating data center polluted a water source as the primary cause. The dirty-water story is really three different stories wearing one coat.
First, the fakes. The viral water towers stamped “you can’t drink data” that ride under every data center story are AI-generated, rated false by Snopes and spread by spam-farm pages. The “Zuckerberg dried up the Rio Grande” claim is false too; New Mexico officials blame drought, and the facility draws municipal groundwater, not the river. A real layer of AI-generated propaganda is now riding on top of real worry, which is its own kind of irony.
Second, the one real image. The brown jars Representative Ocasio-Cortez held up at a 2026 hearing are from Georgia, near Meta’s Stanton Springs campus, and for some residents the water is genuinely bad. But the problems began in 2018 when construction land-clearing started, not when cooling started. That is the distinction that matters. Digging and dewatering an enormous site can pull down the local water table and stir sediment into nearby wells, the same way a highway or a pipeline can. No baseline well study was ever done, no lab analysis of the brown water has been released, and EPA is gathering facts, not investigating. The jars prove a problem exists for those families. They do not prove a data center caused it, and the likeliest mechanism is the construction, not the cooling.
Third, the real chemistry. Operating data centers do produce cooling-tower wastewater carrying biocides, corrosion inhibitors, and dissolved metals, mostly piped to municipal sewers. Ohio wrote the first state permit aimed specifically at it only in late 2025, and nobody tests that discharge for PFAS yet. The closest thing to a contamination case, Amazon’s $20.5 million Oregon settlement, involved cooling water concentrating decades-old farm nitrate, not creating it. Concentrated, not caused.
So the honest verdict on pollution is “mostly no, and barely watched.” No proven case of an operating data center poisoning a water supply. But the monitoring is thin enough that the absence of proof is partly an absence of testing, and that gap, not the fake water towers, is the legitimate thing to push on.
Five places, five verdicts
The Dalles, Oregon. Real, material stress. Google went from 124 million gallons in 2017 to about 550 million in 2025, roughly forty percent of the city. The water is mostly surface supply from the Dog River, not the aquifer, and the local aquifer has been a designated critical groundwater area since 1959, from a 1950s aluminum smelter and cherry orchards, long before Google. No collapse. The real story is a small city structurally dependent on one corporate tenant for its budget and its water planning at once.
Phoenix, Arizona. Real but small, and the alarm figures are inflated. Statewide Arizona data center water is under one tenth of one percent of state use. The widely cited “32 percent increase in water stress” is a conflation: 32 percent is the national share of data centers sited in high-stress areas, not Phoenix’s stress increase, which is quoted as “up to 17 percent” with no baseline. NASA satellite data blames Arizona’s groundwater decline on agriculture and climate. The aquifer is genuinely overdrawn, and data centers are a small, new, and growing line item on a much older bill. Tucson and Marana have already moved to block or limit them, which is the system working.
Northern Virginia. Real, sharpening, but not an aquifer story. The world’s densest cluster used about 1.6 billion gallons of potable water in 2023, up 250 percent since 2019, around ten percent of Loudoun County. It comes from the Potomac, a large surface river, not the stressed coastal aquifer to the east. The credible concern is the trajectory: a regional study projects data center water rising from about 4 to over 20 million gallons a day by 2050, with peak demand landing in summer exactly when the river runs low. About forty percent of these facilities already use air cooling and no water at all.
Palm Beach County, Florida. Prospective only. This is where the gap between alarm and evidence is widest. The data center people fear most here, “Project Tango,” is unbuilt, rescoped, with water figures that range from a county estimate of 1.7 million gallons a month to a developer claim of 5,000 gallons a day, and no permit even filed. Both numbers are unverified, so neither should be quoted as fact. The one documented South Florida aquifer crisis, Cape Coral’s record lows in 2025, was caused by twenty-five years of residential growth, on the record from the water district, with zero data center involvement. Florida already passed a law in 2026 requiring large data centers to use reclaimed water, a precaution taken before any harm, which is the right time to take it.
The control case. Genuinely fine, with one catch. Meta’s Prineville, Oregon campus runs at a water-use rate well below the national average and funded an aquifer storage system holding a year’s buffer. Sited and cooled well, the problem largely disappears. The catch, from that 2026 peaking study: even a cool-climate site can hit more than thirty times its average demand on the hottest summer days, because evaporative cooling only fires a few hundred hours a year, all at once. And Google’s Council Bluffs, Iowa site, in a water-rich state, still used a billion gallons in 2024, because it cools by evaporation. Which is the real lesson of the whole file: good geography helps, but cooling technology is the bigger lever. A water-rich location with evaporative towers can out-drink a desert site that went dry-cooled.

The fix is real, and already moving
The cooling is in transition, not stuck. Old evaporative towers are water-hungry but energy-cheap. Dry cooling uses almost no water but burns more power. Liquid cooling, piping coolant directly to the chips, breaks that old tradeoff: near-zero on-site water and high energy efficiency at once. And the AI buildout is, against the narrative, pushing toward it, because the newest AI chips run too hot and too dense for air cooling to keep up. Liquid cooling took nearly half the new-build market in 2024. The bad news is that thousands of existing evaporative facilities will keep running for years.
“Water-positive” does not mean what you think
Google, Microsoft, Meta, and Amazon have all pledged to be “water-positive by 2030,” replenishing more than they consume. It is the reassuring line in every sustainability report. Stated as a verified, on-track outcome, it is false, for three concrete reasons. Consumption is rising faster than replenishment, with Google’s use up 28 percent in a single year. The accounting leaves out the indirect, electricity-side water entirely, which means at most about a twelfth of the real footprint is even in scope. And the replenishment happens through offset credits in watersheds often nowhere near where the extraction stress actually occurs, with no independent check after the fact. A 2025 policy review called it “obfuscation by complexity.” It is a target a company set for itself and grades itself on. Treat it as a goal, never as a result.
Audit the forecast before you fear it
The biggest projections deserve the same scrutiny as the biggest fears. The widely cited UN estimate of 9.3 trillion liters of data center water by 2030 is real, but about 80 percent of it is indirect power-plant water, it covers all data centers rather than just AI, and it ships with no published methodology or uncertainty range. That does not make it wrong. It makes it unquotable as a hard fact. The honest move with any forecast is the same three checks: what scope is this, direct or indirect; is it AI or all computing; and does it show its uncertainty. A number that cannot answer those is a headline, not a finding.
How to read the next water headline in ten seconds
You do not need a hydrology degree. You need three questions, the same three that organize this whole piece.
Is this withdrawal, or consumption? Only the second one is water actually lost.
Is this the direct cooling water, or the bigger indirect water from the power plant? If they only mention one, they are showing you the smaller, scarier-looking half of the story.
Is this a local number or a national one? Less than one percent nationally and forty percent in one town are both true, and confusing them, in either direction, is how you get played.
Run those three and the panic collapses into the actual problem, which is real and solvable: a small number of facilities, in a small number of water-stressed places, cooled the old way, dependent on a local supply that cannot spare the share. That is a siting and engineering question, not a civilizational water crime. The fight worth having is over where these get built and how they get cooled. Not whether AI is secretly drinking the rivers dry. It is not. But it might be quietly reshaping the budget of a town near you, and that is worth watching closely, with the right number in hand.
And the right photo. The next time a jar of brown water lands in your feed under a data center headline, ask the same kind of question you would ask of a statistic. Did this start with construction or with cooling? Is the image even real? A surprising share of them are not.
Adapt and Create,
Kamil
Sources
LBNL, 2024 US Data Center Energy Usage Report (Shehabi et al.). direct/indirect consumption, WUE, 2028 projections, cooling-market share.
USGS Circular 1441, Estimated Use of Water in the US in 2015. sectoral shares, agriculture ~42% of freshwater.
USGS SIR 2019-5103, Thermoelectric water withdrawal and consumption. the 38:1 withdrawal-to-consumption ratio.
USGS SIR 2024-5120, North Phoenix aquifer. storage decline attributed to recharge, not data centers.
Jasechko et al., Nature 2024, global groundwater. 170,000 wells; irrigation the dominant driver.
Ren et al., “Making AI Less Thirsty,” arXiv:2304.03271. the real per-response water figure behind the “500 mL” misread.
Han et al. 2026, “Small Bottle, Big Pipe,” arXiv:2603.02705. peaking factors; single-facility share of municipal capacity (preprint).
ICPRB 2025 Washington Metro Area Water Supply Study. Northern Virginia projections.
OPB, The Dalles / Google water. the ~40% figure and disclosure fight.
OPB, Amazon Boardman nitrate settlement. the strongest harm case and its agricultural origin.
Ceres, “Drained by Data”. the 32% siting share (often misquoted as a stress increase).
Circle of Blue, Arizona data center water. statewide share under 0.1%.
Construction Physics, “I Was Wrong About Data Center Water”. the hydropower-evaporation caveat on indirect water.
policyreview.info, big tech 2025 sustainability reports. why “water-positive” pledges are not verified.
IEEE Spectrum, the real story on AI water use. how the viral per-query stat went wrong.
UNU-INWEH, Environmental Cost of AI. the 9.3-trillion-liter projection and its scope caveats.
EPA ECHO enforcement database. searched for data-center water-contamination findings; none on record as of mid-2026.
Snopes, AI-generated anti-data-center water-tower images. rated false.
Snopes, “Zuckerberg dried up the Rio Grande”. rated false; drought, not data centers.
CBS Atlanta, Morgan County brown-water samples and EPA. construction-phase onset, causation unconfirmed.
Ohio EPA, first general NPDES permit for data-center wastewater. the operational-discharge regulatory gap.