
KPMG's 100-Page-Prompt AI Disaster Shows What Not to Do
How the Big Four keep turning simple AI wins into governance theater

Hey Adopter,
KPMG just admitted it built a tax advice agent with a 100-page prompt. The system drafts 25-page client documents in one day instead of two weeks, runs on their private Workbench platform, pulls from internal advice plus Australian tax code, and only licensed tax agents can touch it. Their own CDO already admits such mega-prompts "probably won't be necessary" once their agent runtime matures.

Here's what that 100-page prompt actually tells us: the Big Four has no real idea how to implement generative AI in business because they don't understand how it actually works.
This isn't about corporate bureaucracy. This is about technical incompetence disguised as thoroughness.
Operational complexity shows they don't understand LLMs
Large language models perform best with clear, concise instructions.
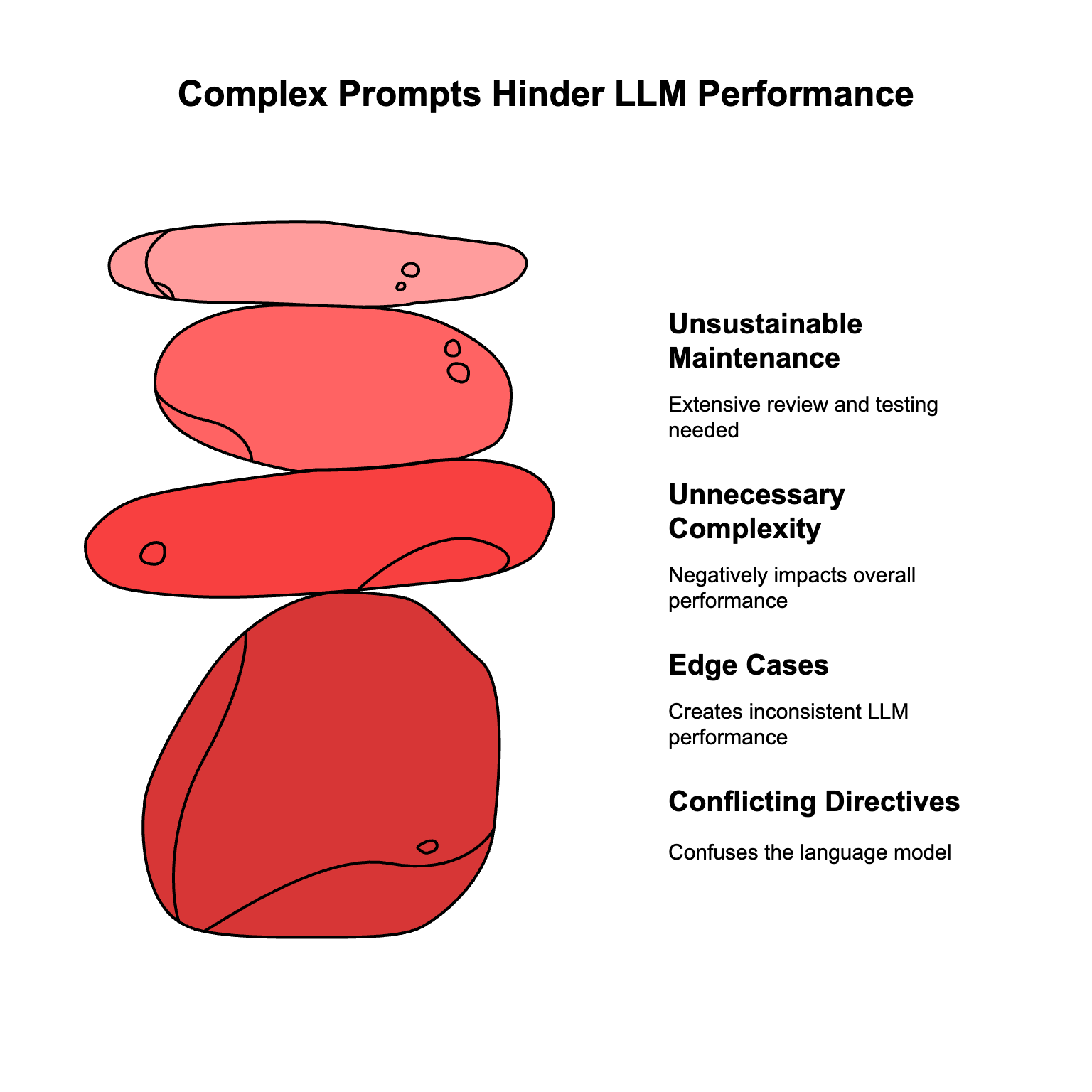
A 100-page prompt indicates a fundamental misunderstanding of how AI systems operate effectively. When you're working with prompts that large, maintained by multiple people, you have conflicting directives, edge cases that confuse the system, and unnecessary complexity that hurts performance rather than helps it.
I've been involved in implementing this technology in hundreds of systems, both for my business and clients. The pattern is always the same: teams that actually understand how LLMs work start with focused prompts and build up systematically. Teams that don't understand create massive instruction documents and wonder why performance is inconsistent.
The maintenance nightmare proves they've never scaled anything.
Managing a 100-page prompt is operationally unsustainable. Every tax law change, regulatory update, or performance issue requires extensive review and testing of the entire document. The complexity makes it almost impossible to identify what's causing problems or implement improvements efficiently.
Compare this to modular prompt design where each component has a single responsibility, clear inputs and outputs, and can be tested independently. When Australian tax law changes, you update one small module, not hunt through 100 pages of prose.
KPMG's approach shows they've never actually built anything that works at scale. They think more pages equal better AI.
Have you seen this same pattern at your company - teams creating massive, complicated systems when simple solutions would work better? Whether it's AI, software projects, or just everyday processes, I'm curious: what's the most over-engineered disaster you've witnessed?
Drop a comment below and tell me about your "100-page prompt" moment.
Bonus points if you can share what the simpler solution should have been.
Use-case misalignment shows dangerous technical judgment
Tax advice demands precision. The bigger the prompt, the higher the chance of unpredictable edge case behaviors.
A single error can lead to serious financial and legal consequences for clients. Large prompts create more opportunities for conflicting instructions, ambiguous edge cases, and unexpected model behaviors that are impossible to predict or test comprehensively.
Personally, I would never use generative AI for tax advice in the first place. But if you're going to do it, you need deterministic, testable components with clear validation at every step. Not a 100-page instruction manual that creates more failure modes than it solves.
The fact that only licensed tax agents can use KPMG's system proves my point. They built something so unreliable that regular people can't touch it. That's not AI augmentation. That's an expensive liability.
The Big Four keeps making the same technical mistakes
KPMG isn't alone in misunderstanding how generative AI works.
PwC Australia banned staff from using ChatGPT for client work, calling it "stochastic" and prone to "inaccuracies." Instead of learning how to use it properly, they banned it entirely. That's like banning databases because SQL queries can return wrong results if you write them badly.
Deloitte Australia delivered a government report with AI-generated fake citations. Anyone who understands how LLMs work knows they're terrible at factual accuracy without retrieval systems and validation. Deloitte apparently didn't know this basic limitation.
EY built their EYQ system with "private environments, domain agents, and heavy risk management." That's not technical architecture. That's governance theater built by people who don't understand the technology they're governing.
The research proves they're doing it wrong
Complex work gets worse with AI when you don't understand the limitations.
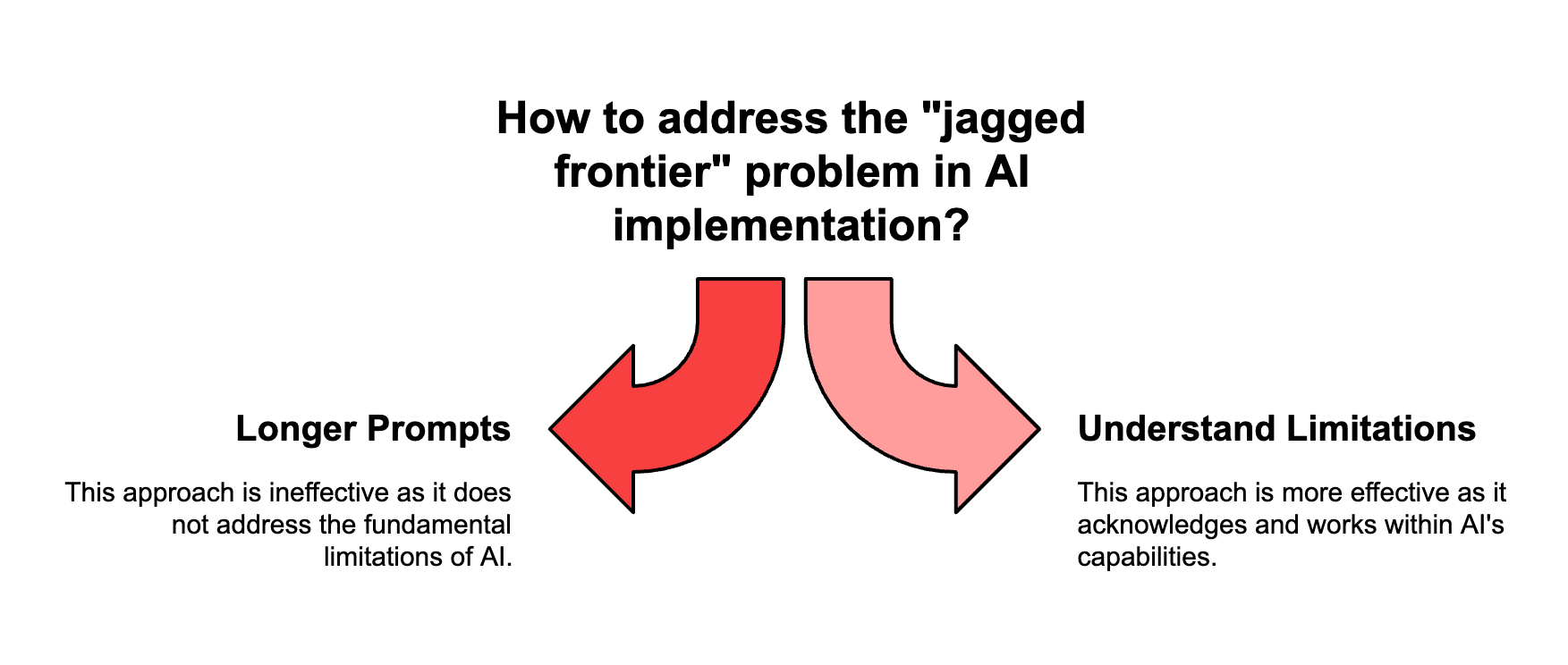
A Harvard Business School study with BCG found consultants' accuracy dropped 19% on complex tasks when using GPT-4. The study calls this the "jagged frontier" - AI is surprisingly good at some tasks and surprisingly bad at others that seem similar.
KPMG's 100-page prompt shows they don't understand this concept. They're trying to solve the jagged frontier problem by writing longer instructions. That's like trying to fix a race condition by adding more code.
Even specialized implementations fail when the fundamentals are wrong.
TurboTax and H&R Block's AI chatbots were wrong or useless up to half the time in Washington Post testing. These companies specialize in tax software and still couldn't get basic AI implementation right.
If dedicated tax software companies can't make it work reliably, what makes KPMG think a 100-page prompt will solve the problem?
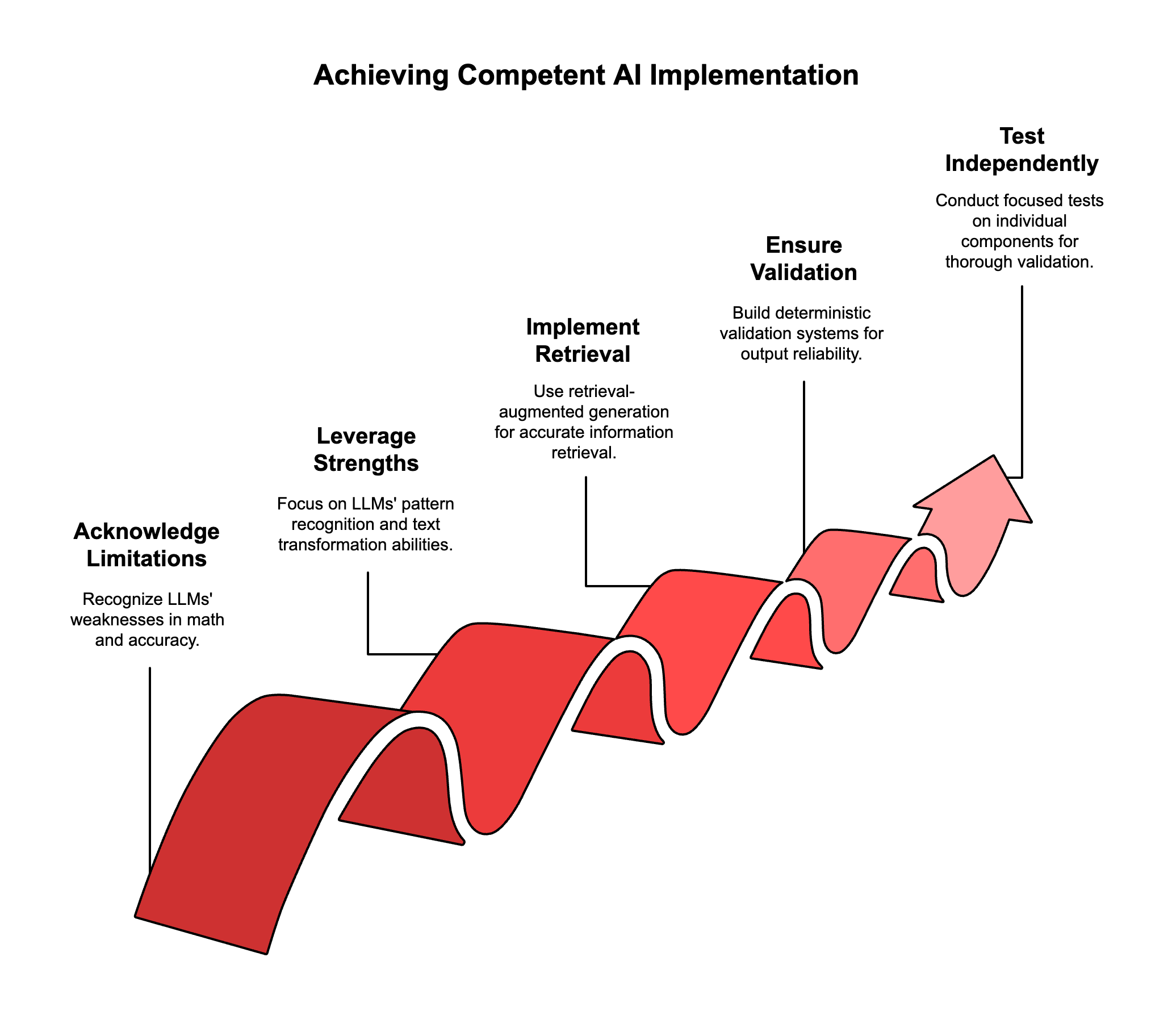
What competent AI implementation actually looks like
Start with the limitations, not the possibilities.
LLMs are terrible at math, citations, and factual accuracy without proper systems around them. They're great at pattern recognition, text transformation, and following clear instructions. Build your system around what they're actually good at.
Use retrieval-augmented generation properly.
Don't ask the AI to remember Australian tax code. Give it the ability to search and retrieve specific passages, then ask it to work with that retrieved information. Separate the knowledge retrieval from the reasoning and generation steps.
Build deterministic validation at every step.
Every output should be checkable. Citations should link to real sources. Calculations should use proper tools, not LLM math. Risk assessments should flag when the AI is operating outside its validated domain.
Test components independently.
Small, focused prompts can be tested systematically. You can validate that document parsing works, that citation retrieval is accurate, that risk flagging catches edge cases. A 100-page monolith can't be tested comprehensively.
The technical incompetence extends beyond AI
KPMG's approach reveals something deeper: they don't understand modern software development practices either.
Version control? Good luck tracking changes in a 100-page prompt maintained by "a substantial team."
Testing? How do you write unit tests for a monolithic instruction document?
Debugging? When something goes wrong, you have to analyze 100 pages to figure out which instruction caused the problem.
Deployment? Every change requires revalidating the entire system because everything is interconnected.
These aren't AI-specific problems. They're basic software engineering problems that have been solved for decades. KPMG is making the same mistakes teams made in the 1990s, just with LLMs instead of databases.
Questions this raises about Big Four technical competence
If KPMG can't implement basic prompt engineering correctly, what does this say about their other technology advice? If they don't understand how AI systems scale, should clients trust them to implement AI strategies?
When Deloitte ships fake citations because they don't understand retrieval systems, are they qualified to advise on AI governance?
When PwC bans AI tools instead of learning to use them properly, do they understand the competitive implications they're recommending to clients?
The real lesson for businesses
The Big Four's AI failures aren't about corporate culture or bureaucracy. They're about technical competence. These firms are selling AI strategy to clients while demonstrating they don't understand the basic principles of how these systems work.
Nothing says "we've never actually built anything that works" like thinking that more pages equal better AI. But hey, at least it'll make an impressive slide deck for the next client pitch.
If you're getting AI advice from consultants who think 100-page prompts are sophisticated, find new consultants. The future belongs to teams that understand both the capabilities and limitations of these tools, not ones that create expensive complexity to hide their ignorance.
Adapt & Create,
Kamil
Why is this surprising? It just shows how generally consulting firms work.
Edrobot@semanta.nl