
Your Voice AI Demo Works Great Until Real Customers Call
Lab accuracy collapses in production and that's where 97% of voice projects actually die



Hey Adopter,
Voice AI is growing 34.8% annually, with businesses handling 20-30% more calls using 30-40% fewer agents. But most projects fail at the layer nobody watches: transcription. Not the conversational design, not the prompts, but getting words from audio into text accurately enough that everything built on top actually works.
This article shows you why transcription accuracy in production determines ROI, how to evaluate providers without getting trapped by lab benchmarks that collapse under real customer audio, and the build-versus-buy decision that determines whether you ship this quarter or spend years debugging.
The layer that separates scaling from stalling
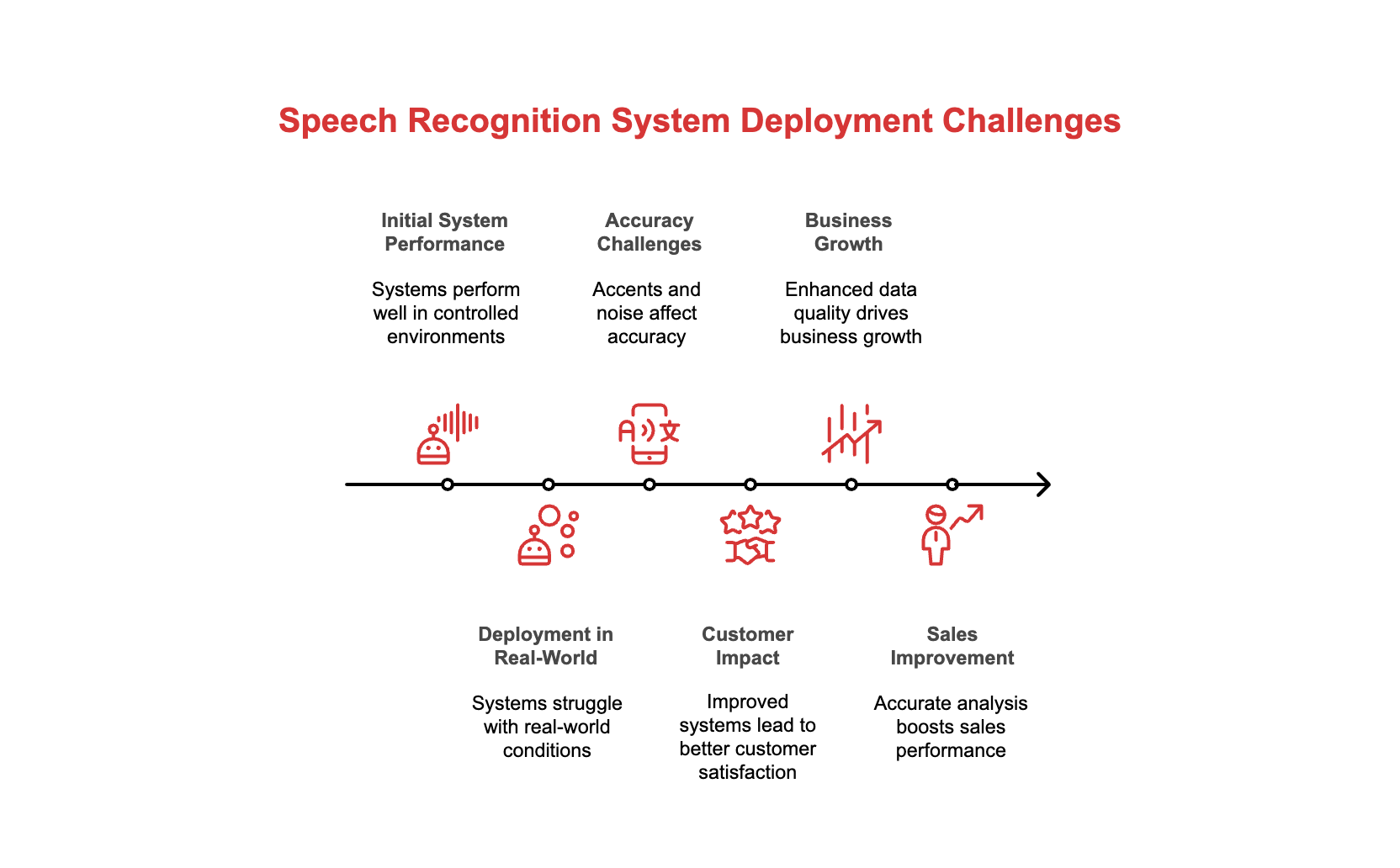
Companies handling 20-30% more calls with 30-40% fewer agents didn’t start by perfecting their AI prompts. They fixed how their system hears customers in real conditions.
Businesses cutting support costs by 30% through voice AI didn’t build better chatbots first. They started with transcription that works on actual customer calls, not demo audio.
Think of it like building a house. You can design beautiful rooms, but if your foundation cracks, everything above it fails. Voice AI is the same. Get the transcription wrong and every feature you build on top inherits those mistakes.
The pattern holds across 97% of organisations now using voice technology. Winners picked reliable infrastructure that handles production audio and moved fast. Losers chased impressive lab benchmarks that collapsed under real-world conditions.
The voice AI market will hit $47.5 billion by 2034, up from $3.14 billion last year. Companies capturing that growth share one strategy: buy the foundation that works in production, build the features that differentiate.
Why lab accuracy and production accuracy are different things
Most speech recognition systems look great in demos. Clean audio. Clear speech. No background noise. Perfect phone connections.
Then you deploy them on real customer calls and everything breaks.
Speech recognition accuracy across different accents and speaking styles is a major challenge. So is background noise interference. Language complexity matters. Regional dialects matter. Phone quality matters.
Your customers don’t call from quiet rooms speaking clearly. They call from cars, busy offices, construction sites, retail floors. They have accents. They mumble. They use industry jargon your system has never heard.
The gap between lab performance and production performance is where most voice AI projects die.
Dovetail runs a customer intelligence platform. They improved their transcription infrastructure and immediately saw customer satisfaction climb. They didn’t change their analytics. They just started processing clean data for the first time.
CallRail tracks marketing calls for thousands of businesses. After upgrading their speech recognition, they saw explosive growth. Why? Their customers finally got accurate data from messy real-world calls. Better transcripts meant better business intelligence.
Jiminny builds tools that analyse sales calls. Their customers using the platform close 15% more deals and report 51% higher satisfaction. The coaching methodology didn’t change. The system just started reliably capturing what was actually said in real sales conversations.
What breaks first in production
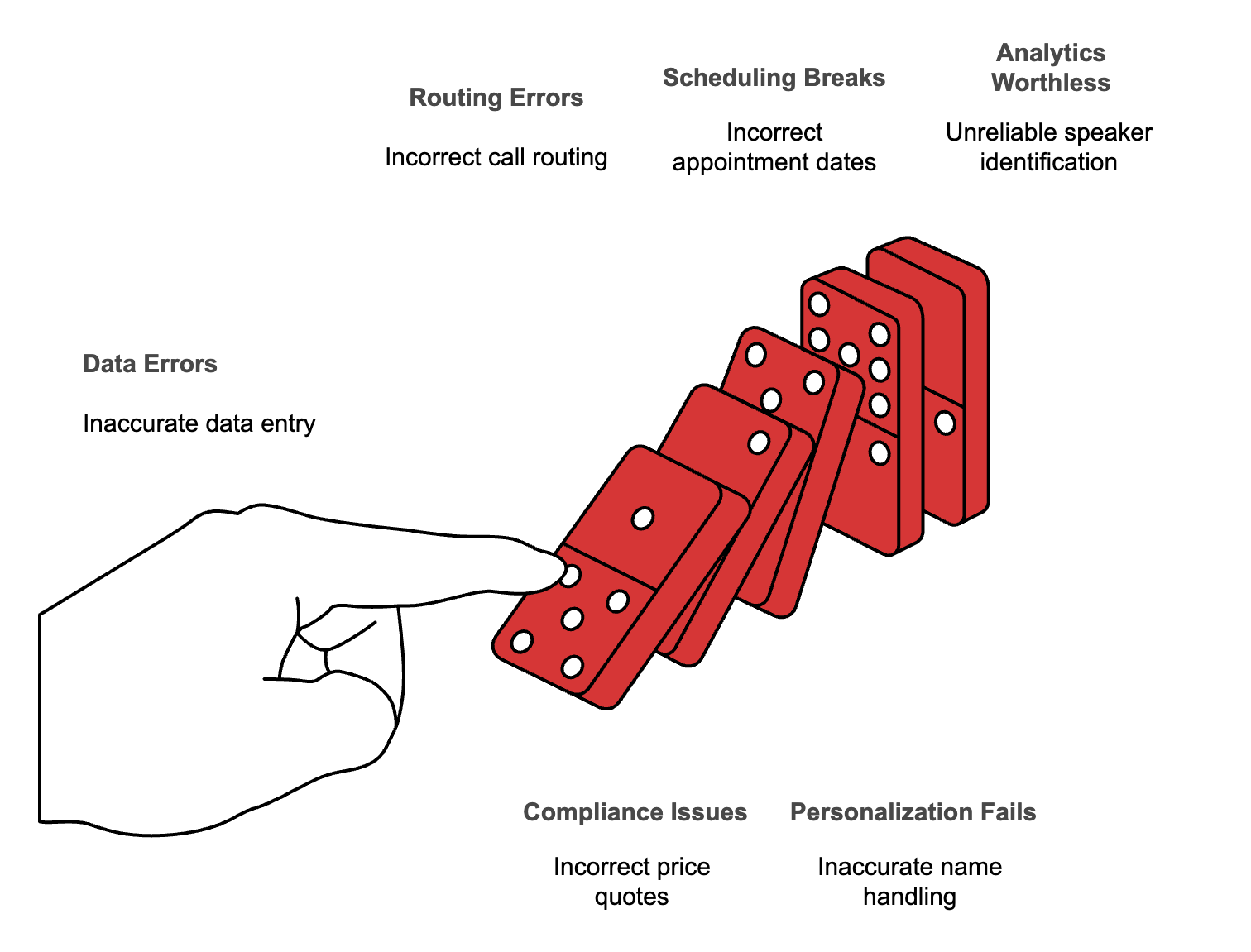
Numbers get mangled
Account numbers, phone numbers, monetary amounts, dates, times. These matter most to your business logic and they’re exactly what most systems struggle with.
One wrong digit in an account number routes the call incorrectly. One wrong number in a price quote creates compliance issues. One wrong date in an appointment breaks your scheduling.
Names become gibberish
Customer names, product names, company names, location names. If your system can’t handle diverse names accurately, your entire personalization layer fails.
Technical terms turn to nonsense
Industry jargon, product SKUs, medical terms, legal language, financial terminology. Every industry has specialized vocabulary that general-purpose systems miss.
Speaker identification breaks
If you can’t reliably tell who said what, your conversation analytics are worthless. You can’t track objections. You can’t measure talk ratios. You can’t coach based on what actually happened.
The make-or-buy decision that determines your timeline
Companies building voice AI face a critical choice: build your own speech recognition or use a specialist provider. It is equally important for you to know when choosing between vendors.
Building your own means:
Hiring machine learning engineers (expensive, scarce talent)
Collecting and labelling thousands of hours of audio
Training models to handle different accents, phone quality, and background noise
Maintaining the system as it breaks in production
Adding new languages one by one
Debugging why it fails on your specific customer audio
Timeline: 18-36 months. Budget: millions in salaries and infrastructure.
Using a specialist provider means:
Integrating an API
Testing it works with your production audio
Shipping features to customers this quarter

Calabrio provides workforce analytics to call centres. They built their own speech recognition years ago. It worked in their lab. Then they switched to a modern provider built for production conditions. Customer satisfaction jumped 80%. They expanded globally faster. And their developers spent 62.5% less time on transcription problems.
That time didn’t disappear. It went into features that customers actually pay for.
EdgeTier builds conversation analytics for customer service teams. They tripled their enterprise deals without hiring more engineers. They didn’t get better at sales. They freed their team from maintaining infrastructure and focused on solving customer problems.
What actually matters when evaluating providers
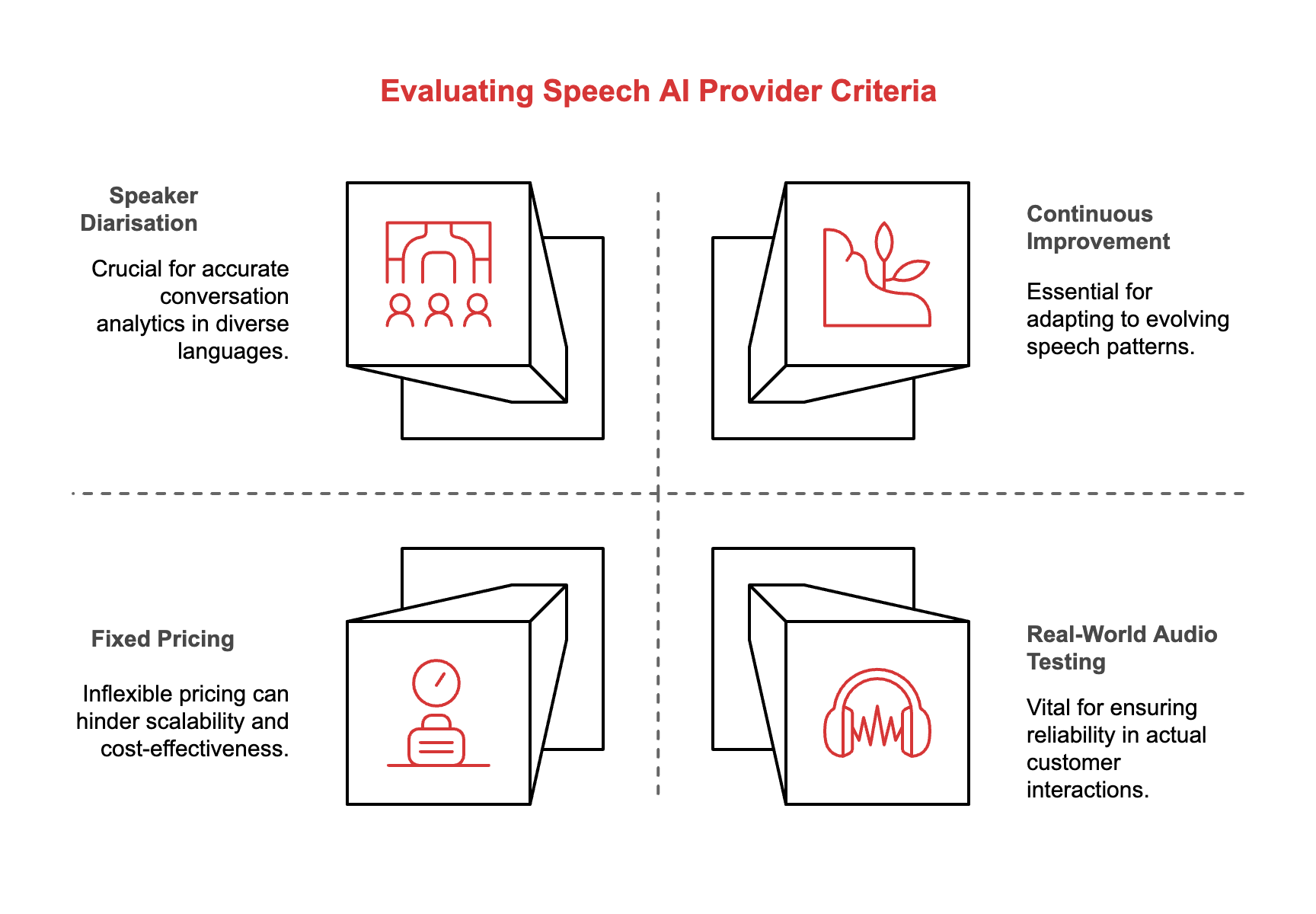
Performance on your audio, not theirs
Vendors show you demos with perfect audio. Test them with your actual customer recordings. Accents, background noise, industry jargon, phone quality, overlapping speakers.
The only accuracy number that matters is performance on your production audio.
Zoom uses speech AI to improve their meeting features. WhatConverts powers their entire call tracking business on reliable transcription. These companies tested on real messy audio before committing.
Knowing who said what across languages
Speaker diarisation separates your agent from your customer, identifies multiple speakers in conference calls, and tracks who said each sentence. Without this, conversation analytics break.
If you operate globally, you need this working across dozens of languages. Not just English. Not just major European languages. The languages your actual customers speak.
Siro builds coaching tools for field sales teams. They needed a system that could identify speakers in noisy field environments across multiple languages. Once they had that working, their coaching insights became valuable.
Continuous improvement, not static performance
Speech recognition isn’t a solved problem. Languages evolve. New accents emerge. Industry terminology changes. Phone networks upgrade. New use cases appear.
You need a provider that ships improvements continuously. Adds languages. Reduces errors on edge cases. Optimizes for new patterns emerging in your audio.
Pricing that doesn’t trap you
If you charge customers based on usage, you can’t afford fixed annual commitments. You need pricing that scales with your revenue, not against it.
Pay-as-you-go matters. Start small, test with real customers, scale if it works, and only pay for actual usage.
In partnership with AssemblyAI
Why leading platforms partner with AssemblyAI
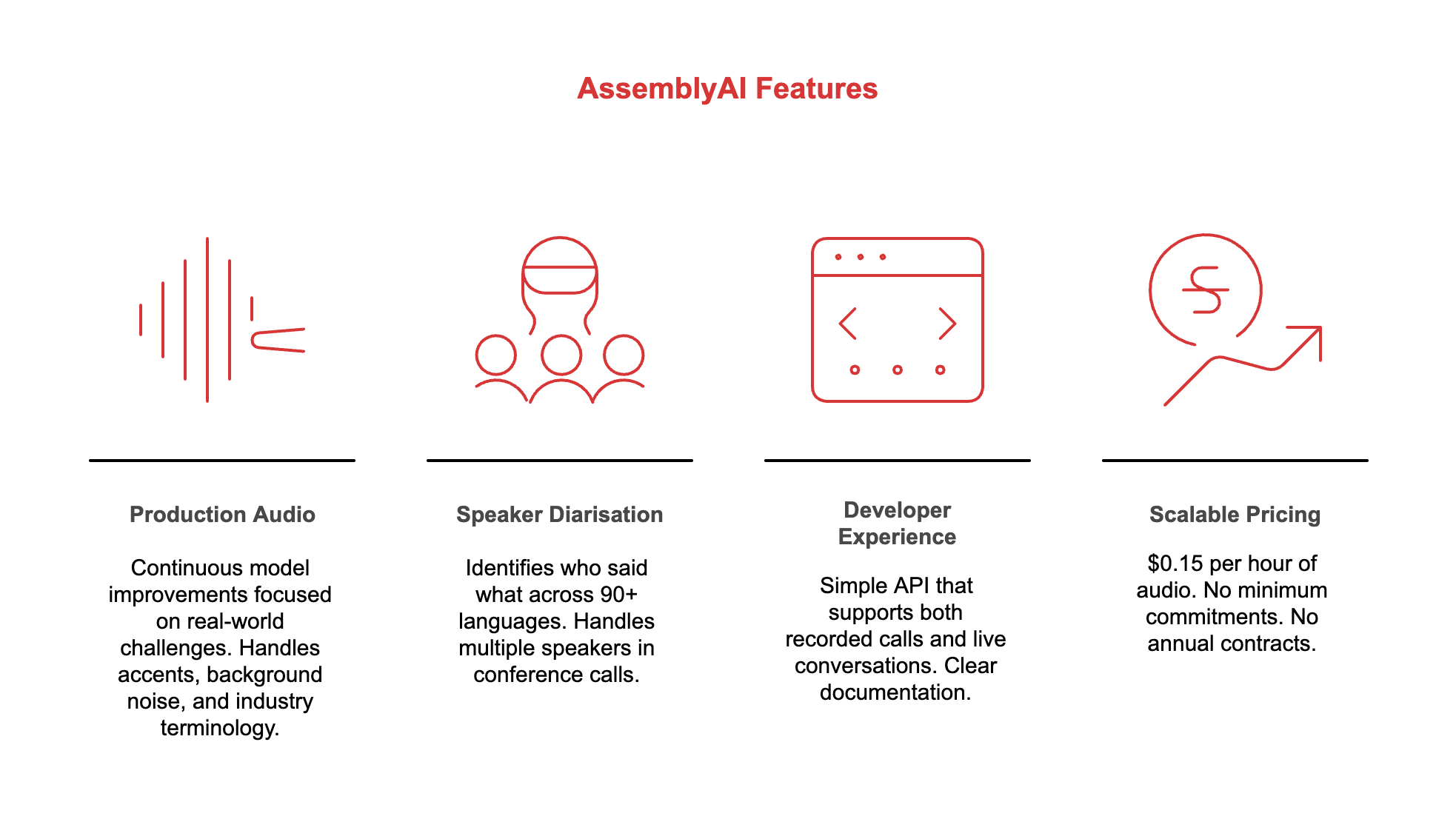
The companies mentioned above, Calabrio, CallRail, EdgeTier, Jiminny, Dovetail, Zoom, WhatConverts, and Siro, all use AssemblyAI to handle speech-to-text in production.
Built for production audio, not lab conditions: Continuous model improvements focused on real-world challenges. Handles accents, background noise, and industry terminology. Optimized for the messy audio that actually flows through your systems. Regular updates add new languages, reduce errors on edge cases, and improve formatting for business use cases.
Multilingual speaker diarisation at scale: Identifies who said what across 90+ languages. Handles multiple speakers in conference calls. Works reliably even with overlapping speech and challenging audio conditions. Critical for conversation analytics, coaching tools, and compliance monitoring.
Developer experience that accelerates shipping: Simple API that supports both recorded calls and live conversations. Clear documentation. Works for both async (pre-recorded) and streaming (real-time) transcription. Built for teams who need to ship fast without becoming speech recognition experts.
Pricing that scales with your business: $0.15 per hour of audio. No minimum commitments. No annual contracts. No penalties for low usage months. Unlimited concurrency. You pay for what you use, when you use it. This matters when you’re charging customers based on AI features, your costs need to match your revenue.
Aloware runs contact centre software. After switching to AssemblyAI, they converted 50% of their customers to their new AI packages. Supernormal captured market share by offering better multilingual support than competitors. Grain built their entire conversation intelligence product on this foundation.
Speed to market determines winners. Kapwing’s technology chief says their success with AI features came from partnering with infrastructure that accelerated development. Earmark launched real-time meeting transcription without spending years building speech recognition.
You can test it yourself in their playground. Upload your actual customer call recordings. See how it handles your specific audio. Check performance on the edge cases that matter to your business: numbers, names, technical terms, accents.
Shipping fast beats building everything yourself.
Where to start your evaluation
Test with real customer audio
Don’t trust vendor demos with perfect audio. Record 20 actual customer calls. Run them through different providers. Check which one handles your specific challenges.
Pay special attention to what breaks most systems: account numbers, phone numbers, dollar amounts, customer names, product SKUs, industry jargon.
Check language coverage
If you operate across countries, you need accurate transcription and speaker identification in multiple languages. Building this yourself takes years. Buying it takes one integration.
Calculate costs at scale
Model your pricing at 10X current volume. What does it cost at 10,000 hours per month? At 100,000? Make sure your unit economics work as you grow.
Measure integration speed
How long to get a working prototype? How clear is the documentation? Can one developer get this running in a week, or do you need a dedicated team for months?
The opportunity hiding in infrastructure decisions
Ninety-seven per cent of organisations already use voice technology. The market is growing 34.8% every year. Companies that picked a reliable transcription infrastructure built for production audio are shipping new features every quarter. Their competitors are still debugging why their system fails on regional accents.
The market rewards solving customer problems faster, not building everything in-house.
You face the same decision everyone building voice AI faces: own the entire technology stack or partner for the foundation layer.
Owning speech recognition means 18-36 months of development before you ship anything.
Partnering for speech recognition means shipping features this quarter and learning what customers actually want.
The companies handling 30% more volume with 40% fewer staff, cutting support costs by a third, and tripling their enterprise sales made the second choice.
Test your options with production audio, pick infrastructure that handles real-world conditions, and focus your team on what makes you different from competitors.
Adapt & Create,
Kamil
Hy
This is such a clear reminder that the foundation matters. Accurate transcription in real-world conditions is what makes voice AI actually deliver value. Thanks for breaking down the gap between lab demos and production realities; so insightful!