
Why Your GPT-5 Outputs Are Shallow or Bloated (and how to fix it)
The router picks reasoning depth and length separately. Control both explicitly.

Hey Adopter,
GPT-5 launched months ago. Most users still don’t know why their results got worse. Today, you’ll learn the architectural change OpenAI made, plus copy two instruction types that force better outputs.
The fundamental shift nobody explained
GPT-4 tolerated vague prompts. It guessed your intent and compensated for missing details. GPT-5 flipped this. It follows precise instructions better than any previous model but performs worse when you’re vague.
This isn’t a bug. OpenAI built GPT-5 for AI agents where ambiguity breaks automation. An agent updating cell B7 in a spreadsheet can’t interpret, it must execute exactly.

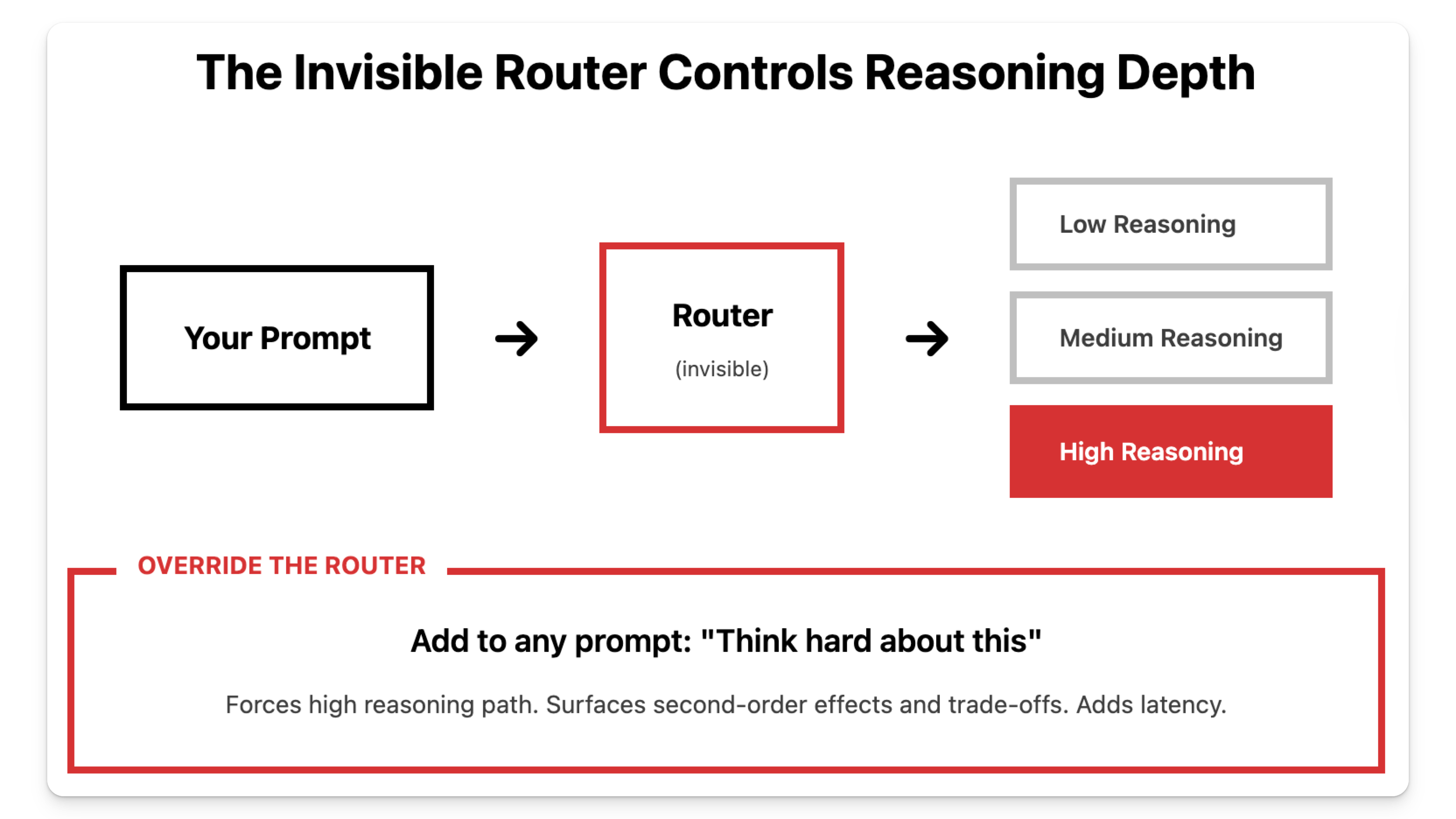
The second change compounds the problem. GPT-5 routes every request through an invisible selection system. This router picks which processing level handles your task. Default routing optimizes for speed and cost, not output quality.
Your casual prompting style now collides with literal instruction-following and cost-optimized routing. Result: shallow analysis or bloated responses.
The fix is simple. Two instruction types override the defaults. First, force deeper processing when stakes matter. Second, set exact output boundaries every time.
The router controls two separate dials
Understanding the architecture helps. Your prompt hits a router that makes two independent decisions: reasoning depth and output length.
Reasoning depth: Low, medium, or high processing intensity. Higher reasoning surfaces second-order effects and trade-offs. Lower reasoning stays surface-level.
Verbosity: Low, medium, or high output length. This controls word count independent of how deeply the model thinks.
Most users let the router pick both settings automatically. The router defaults to low reasoning and medium verbosity because that’s cheapest for OpenAI to run. You pay the same subscription either way.
The fix is forcing both dials to specific settings using explicit phrases.
Analysis triggers that force deeper reasoning
Add one phrase to any prompt where missing implications costs you. This overrides the router’s default and pushes reasoning to high.
Three phrases that work:
🟩 Think hard about this.
🟩 Think deeply about this.
🟩 Think carefully.These phrases are explicit. They tell the model exactly what cognitive process to apply. You’ll see a processing indicator appear. The output will surface implications, trade-offs, and second-order consequences instead of surface observations.

Phrases that fail:
🛑 This is critical.
🛑 This is very important.These phrases are vague. They emphasize importance but don’t specify what action to take. GPT-5 trained on precise instructions. Vague emphasis doesn’t register as a command.
Use for: Financial decisions, planning work where missed dependencies cause delays, risk evaluations, strategic choices with compounding effects, technical architecture.
Test it: Ask about parking $200K in treasury bills versus a high-yield savings account. Without the trigger, you get basic pros and cons. With it, you get tax treatment differences, liquidity trade-offs, and structured decision criteria.
Trade-off: Higher processing time and token cost. Use only when getting it wrong once is more expensive than the compute time.
Output specifications that control the verbosity dial
Set the second dial explicitly. The router’s default medium verbosity produces bloated responses for executives and insufficient context for teams.
Use specific phrases that state exact word counts or paragraph ranges. GPT-5 respects precise boundaries better than earlier models.
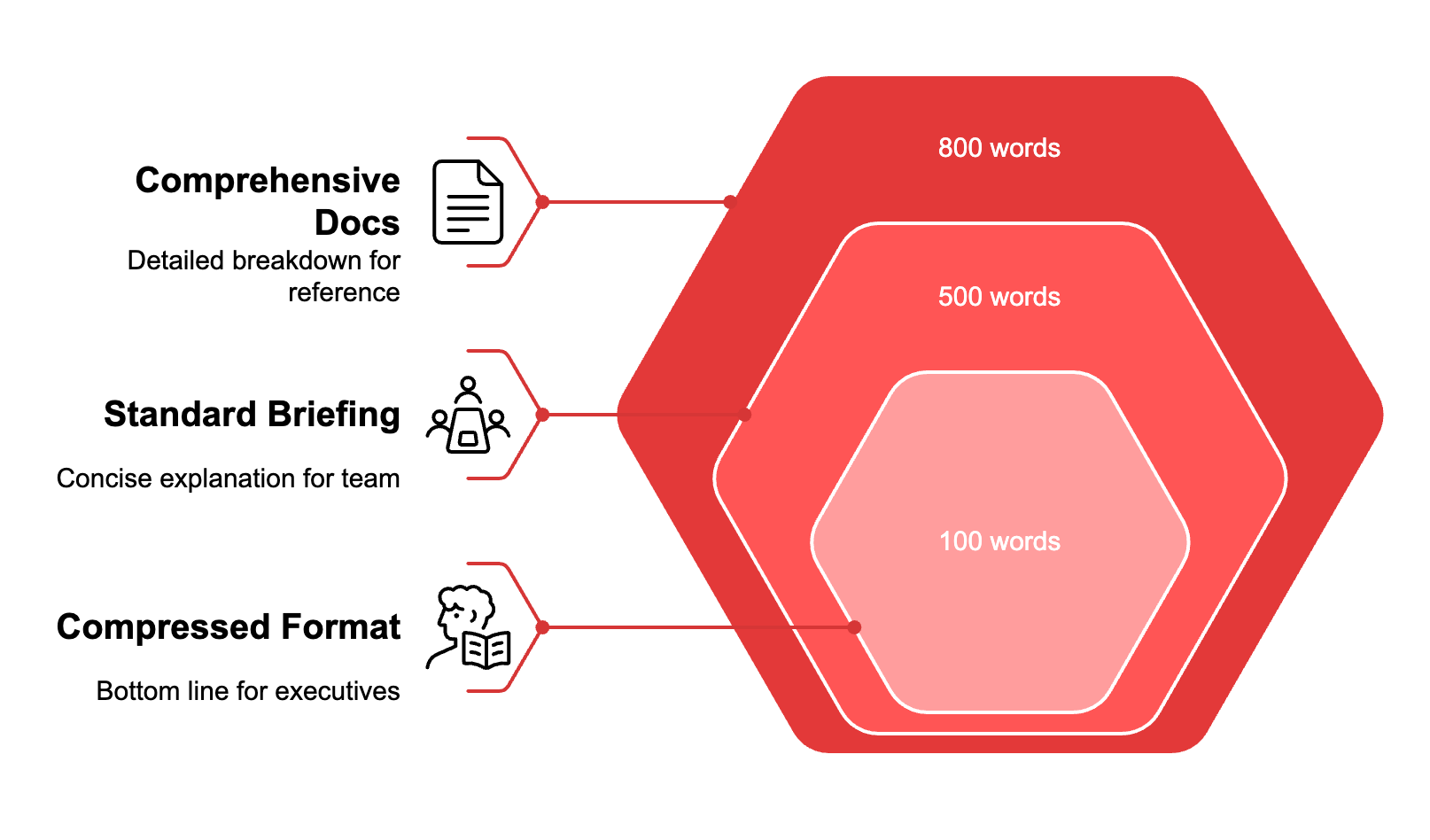
Compressed format for senior stakeholders:
Give me the bottom line in 100 words or less. Use markdown for clarity and structure.Use for executive updates, leadership Slack, anything senior people scan in under 30 seconds.
Standard briefing for team coordination:
Aim for a concise 3 to 5 paragraph explanation.Use when colleagues need to understand causation, not just results. Conversion rates up 30% but click-through down 18%, they need enough context to adjust tactics.
Comprehensive documentation for reference:
Provide a comprehensive and detailed breakdown, 600 to 800 words.Use for project charters, research digests, materials multiple teams will reference over weeks.
Bonus: A meta prompt for high-stakes work
For presentations, client proposals, and strategic plans, add this:
